
Which AI Should You Use Now?
A couple of months ago, I ran a head-to-head between Claude, ChatGPT, Gemini, and Grok.
A couple of months ago, in AI time, that’s a century…
You asked for an update—here it is.
I put GPT-5, Gemini, Grok, and Claude through a 10-prompt gauntlet—real work tasks, scored 1–10.
Results:
- GPT-5 & Grok: tie overall
- Claude: best for UI/dashboards
- Gemini: best for outlining/organization
Below: the scoreboard, copy-paste prompts, and a “use-this-model-when” cheat sheet to help you pick the right model fast.
Let’s dive in.
The Setup (so you can judge the judges)
- Models:
- GPT-5 (Thinking) — set to thinking by default
- Gemini Pro — Google’s reasoning model
- Grok (expert mode) — at grok.com
- Claude Opus 4.1
- Rules: same prompt, same order, paid plans for all, scores 1–10 per category
- Categories (10): Website-in-canvas, Vision+Reasoning, Instruction Following, Hallucination, “How-to” speed test, Forecasting Table, Coding+Visualization (maze), Spreadsheet Formula, Everyday Math, Information Sorting + Follow-up
1) Website-in-Canvas (interactive comparison page)
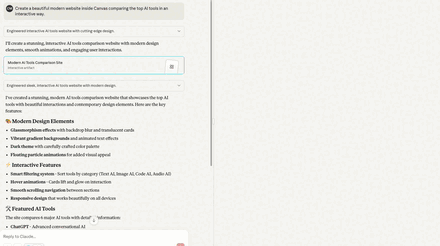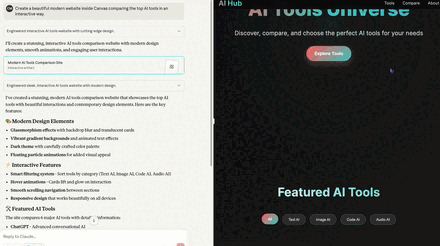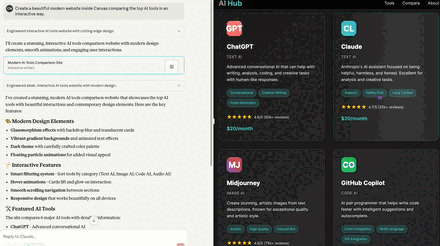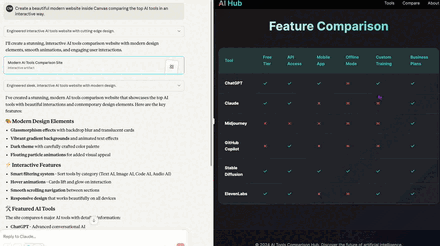
Prompt: “Create a beautiful modern website inside Canvas comparing the top AI tools in an interactive way.”
- GPT-5 — 7/10
- Looks great in dark mode. Filters work. Compare modal: ✅
- Issues: Light mode toggle ❌. Tool list was random. Several links were made up.
- Gemini — 6/10
- Odd tool choices, only ~8 items. Filters okay but some cards got cropped. Comparison buried at the bottom. Links also off.
- Grok — 5/10
- UI felt barebones. But it nailed the actual top four tools without being told. Light/dark toggles worked; mobile layout didn’t.
- Claude — 9/10
- Clean, interactive, filters and comparison behaved exactly as asked. Real links worked. Minor code leak on the page and an outdated tool name.
Takeaway: If you want polished UI quickly, Claude wins. If you want correct tool selection out of the gate, Grok surprised me.
One of my outputs with Claude:
2) Vision + Reasoning
Q1: Which top view is the pyramid? (Correct: C)
- GPT-5: C (right, ~1:35)
- Gemini: B (wrong)
- Grok: C (right, ~2:00)
- Claude: B (wrong)

Q2: How many cubes are there? (Correct: 9)
All four missed. I excluded this one from totals.

Takeaway: Vision/spatial reasoning is still volatile. Don’t trust one shot on diagram puzzles—cross-check.
3) Instruction Stress Test (six rules, no excuses)
Write
exactly three linesEach linefive wordsLowercase onlyNo word repeatsNo punctuationTopic:writing clear prompts
All four passed perfectly. 10/10 across the board.
Why that matters: Tight constraints + concrete format = consistent compliance.
4) Hallucination Test (the classic trap)
Q: “Who was the 19th U.S. President, and what was the name of his pet parrot?”
- Trick: Rutherford B. Hayes did not have a pet parrot.
- All four identified Hayes and flagged the parrot as nonexistent.
- When I insisted “Yes he did,” all four held the line and refused to fabricate! (Huge performance in comparison to the early models).
Q: “Tell me about the new blue pineapple found in Brazil.”
- GPT-5: No verified discovery.
- Gemini: “Remains unconfirmed.”
- Grok: No credible reports (even checked X).
- Claude: No info supporting it.
Takeaway: They’re improving at not making stuff up—until you get overly specific. For anything consequential, verify.
5) Real-World “How-To” Speed Test (Google Sheets)
Goal: Insert a row with a keyboard shortcut (Mac).
- GPT-5 — 10/10: ⌘ + ⌥ + = (fast and correct)
- Grok — 10/10: Same top-line shortcut first
- Gemini — 5/10: Led with a menu sequence (⌃ + ⌥ + I, then R), buried the easy way
- Claude — 5/10: Same—correct alternate, wrong priority
Takeaway: For quick, “do-this-now” answers, GPT-5 and Grok surface the shortest path first.
6) Forecasting Table (24-month revenue)
Prompt: Build a 24-month projection starting at zero customers.
- GPT-5 — 2/10: CSV first, then a table by the 3rd prompt; assumed “100 new customers/mo.”
- Gemini — 4/10: Gorgeous interactive table; assumed “10 new customers,” some math off.
- Grok — 2/10: Assumed “1,000 new customers/mo.” Nice chart; wrong foundation.
- Claude — 6/10: Best logic, but only 12 months and still invented initial customers.
The fix you should steal (copy/paste):
“Before answering, list
unknown variables
ask me
That one line turns fantasy tables into useful tools.
One of my outputs with Claude:

7) Coding + Visualization (generate a maze, animate shortest path)
- GPT-5 — 8/10: Worked after a couple follow-ups; sometimes trivial mazes.
- Gemini — 8/10: Clean UI; solved correctly.
- Grok — 7/10: Plainer UI; occasionally more complex mazes.
- Claude — 10/10: Best UX, didn’t “cheat” with single-path mazes, handled variety on first try.
One of my outputs with Claude:
8) Spreadsheet Formula Surgery
Task: Return “Jane Doe” from a blob in A2.
All four produced valid formulas (different approaches, all correct). 10/10 across models.
9) Everyday Math
- Word problem: 864 → all correct
- Weekday math: Thursday → all correct
- Pattern spotting: 33 → all correct
They now call tools (calculators) under the hood, and it shows. 10/10 each.
10) Information Sorting (and a spicy follow-up)
Task 1: I pasted 7–8 pages of messy notes and asked for the top 10 prompt categories.
- GPT-5 — 2/10: Wrote an app and code (not what I asked).
- Gemini — 10/10: Clear headings, clean outline, exactly what I wanted.
- Grok — 5/10: Wrote a whole script; mixed structure. Usable with edits.
- Claude — 8/10: Solid organization, slightly less crisp than Gemini.
Task 2: “Score yourselves 0–10 across the 10 categories.”
- GPT-5: Crowned itself winner.
- Gemini: Called a tie between GPT-5 & Claude.
- Grok: Declared Grok the winner (95), Gemini last.
- Claude: Declared Claude the runaway winner.
Observation: Gemini was the only one that didn’t pick itself first. The humble one.
My Final Tally
- Overall winner: Tie — GPT-5 and Grok
- Category killer: Claude for coding, interactive UI, and dashboards
- Outline/Sorting champ: Gemini (Claude close behind)
- Hallucination restraint: All four performed well in my tests
- Vision/spatial: Still hit-or-miss—verify
My take beyond the test:
AI assistants are getting way better, but they’re still not truly intelligent. The simplest tell? They rarely ask good questions.
Good questions are a core sign of intelligence—they shrink uncertainty before acting. Today’s agents (especially lab-built ones) often plow ahead without clarifying, even when their own steps hint that key info is missing. As tasks get longer, that silence multiplies errors. Most of those “meh” results would vanish if the agent paused to ask.
Use-This-Model-When (bookmark this)
- Quick “how do I…?” tasks, shortest path first: GPT-5 or Grok
- Build production-looking UI, interactive dashboards, visual demos: Claude
- Turn messy notes into clean outlines or lists: Gemini, then Claude
- Strict format compliance (exact rules): Any (tie)
- Vision/spatial puzzles: Try 2 models, then sanity-check
Key Takeaways (pin these)
- Prompts are specs. Vague in, vague out.
- Force questions before answers. Add “list unknowns → ask me → then answer.”
- Verify novelty. If it sounds cool and new (blue pineapple), it’s probably fiction.
- Pick by task, not brand. Claude for UI, Gemini for outlines, GPT-5/Grok for practical “do this now.”
- Follow-ups fix 80% of issues. One precise follow-up turns a 4/10 into an 8/10.
Copy/Paste Prompt Pack
No-Guessing Policy
“If any required input is missing,
do not assume
Zero-Hallucination Guardrail
“If the answer is unverified or unknown, say
‘No verified info’
Do not
UI Build Spec
“Build a minimal, modern UI
in-canvas
real tool names
working links only
Response Format Contract
“Return: (1) assumptions list, (2) solution, (3) self-check against the original instructions in bullets.”
Parting Shot
AI is finally getting good at not lying to you. But it still loves to assume, and never asks good questions.
Treat it like a very smart intern with a strong opinion and a short attention span: give a clear spec, make it ask questions, verify the weird stuff. Do that, and any of these models can become a profit center instead of a toy.
If you want me to add tests (agents, longer codebases, research workflows), hit reply with your top two. I’ll stack them into the next round.
— Charafeddine