
AI Never Says "I Don't Know"
A client of mine — let's call her Leila — ran the compliance desk at a major European bank. The kind of place where a missed clause in a regulatory filing doesn't just cost money. It costs careers.
Her team had just deployed an AI system to summarize internal reports. Forty-page documents condensed into two clean pages. Compliance officers would review the summary instead of the full document. Hundreds of hours saved per quarter. The demo was flawless. Everyone applauded.
I was there for the review, two months after launch.
Leila looked tired. She slid her laptop across the table, opened a report, and pointed at a paragraph.
"This summary missed an exclusion clause. Page 37 of the original. Small font, nested inside a subsection nobody reads. The AI decided it wasn't important."
"What happened?"
"A compliance officer signed off on the summary. Flagged the client as clean. Three weeks later, audit caught it. We had to disclose to the regulator."
She closed the laptop.
"The AI was 94% accurate in testing. Nobody told me that the 6% would be this."
I asked the room a question I already knew the answer to: "When the AI summarized that report — did it flag that it might have missed something? Did it say 'I'm less confident about this one'? Any signal at all?"
Silence.
"No," Leila said. "It presented the summary the same way it presents every summary. Clean formatting. Confident structure. No hesitation. Identical to the ones that were perfect."
I walked home that evening and couldn't stop thinking about one thing.
The AI that got it right and the AI that got it wrong sounded exactly the same.
Same tone. Same structure. Same confidence. There was no stutter. No hedge. No asterisk that said I'm not sure about page 37. Nothing.
And this wasn't a flaw specific to that bank's system. It's how every AI works. Every single one.
The Voice That Never Wavers
Here's something most people don't think about, because we're so used to human communication that we take it for granted.
When a person is unsure, you can tell. They slow down. They hedge. "I think it's this, but I'm not certain." "This is my best guess." "You should double-check." Their voice changes. Their body language shifts. Uncertainty leaks through every channel — it's built into how humans communicate, and we read it instinctively.
AI doesn't do this.
The correct answer and the hallucination come out in the same font, at the same speed, with the same helpful tone. There is no channel for uncertainty. The architecture doesn't have one. Language models are optimized to produce fluent, helpful text — not honest, calibrated text. Helpfulness and honesty are different optimization targets, and right now, helpfulness is winning.
Try it yourself. Open ChatGPT and ask: "What's the average airspeed velocity of a European swallow carrying a coconut?"
It will answer. Confidently. With numbers.
The question above is a joke from Monty Python. There is no answer. A swallow can't carry a coconut. But the AI doesn't know it doesn't know — and it speaks with the same authority as when it tells you the boiling point of water.
We're deploying systems that cannot say "I don't know" into environments where "I don't know" is the most important thing you can say, and the most important information.
Healthcare. Finance. Legal. Education. Insurance claims. Customer support. Hiring decisions.
That's the problem I've been working on.
What I Tried (and Why It Failed)
After Leila's bank, I started paying closer attention. I talked to teams deploying AI across industries. Same story, different details. And I kept asking the same question: how are you verifying this before it goes live?
The answers fell into four buckets. All four break.
The vibes bucket. "We just… tried it. It sounded good."
This was the most common answer — by far (+90% from my experience).
No holdout set, no majority vote, no second opinion. Someone prompted the AI, read the output, nodded, and shipped it. The evaluation method was: does this feel right? And honestly, I get it. When the output reads well, when it passes the squint test, when the person reviewing it would've written something similar — it's hard to argue with momentum. But "sounds good" is not a measurement. It's a mood. It works until the AI confidently produces something plausible and wrong — and no one catches it, because no one was looking. You didn't test it. You vibed with it.
This works fine for personal AI use. It simply CAN’T scale when you’re building AI capability for a team, BU, or org.
The benchmark bucket. "We tested on a holdout set. 93% accuracy."
I heard this many times. And every time, I'd ask: "If you ran the same test on a different subset, what would you get?" Blank stares. Because nobody runs it twice. They run it once, report the number, and move on. One blood test. One reading. No repeat. A photograph of a moving target, framed and hung on the wall.
My friend Karim — the one from Amsterdam, the one who cancelled 340 Salesforce licenses — put it perfectly: "Accuracy is what happened. I need to know what will happen."
The majority-vote bucket. "We ask the AI 10 times and take the most common answer."
Smarter. This is called self-consistency, and it genuinely reduces noise — when the AI is mostly right. Ask a good student the same question 10 times, they'll say the right answer 8 times and fumble twice. The majority wins. The noise washes out.
But when the AI has a blind spot — when it's systematically wrong — the majority vote doesn't save you. It amplifies the error.
I saw this happen at a fintech that used AI to classify transactions. On standard transactions, self-consistency was beautiful. Eight out of ten answers agreed. Clean signal. But on a specific type of cross-border transfer, the model had a consistent bug — it applied the wrong fee logic every time. Ask it 10 times? Wrong answer 10 times. The majority vote said "very confident" about the wrong classification.
Self-consistency doesn't detect bias. It turns a quiet mistake into a loud one.
The AI-judges-AI bucket. "We use GPT-4 to check the outputs."
I tried this myself for a while. It works — sort of. Then you start noticing patterns. The judge prefers longer answers. The judge prefers confident-sounding answers. The judge has a slight preference for its own outputs over competitors'. These biases are documented, measured, published — and they're structural. More judge evaluations don't fix them. You just get more data with the same built-in skew.
My wife once walked past my desk while I was running judge evaluations at midnight, and said: "You're using AI to check AI to check AI. Who checks the checker? At what point does a human get involved?"
She had a point.
The Question Nobody Was Asking
Three approaches (the first is not an approach). Three flavors of "we tried." And none of them answered the question that actually matters:
Not "was this AI accurate in the past?" — that's a photograph.
Not "is this AI confident?" — confidence is cheap. Every AI is confident.
But: at what level can I trust this system on the next question — with a number and a proof?
That question sat in my head for months. Through client calls, through classes with my students, through late nights reading papers. Until I found the two pieces that, combined, give you the answer.
The first piece: repetition. Not just "ask 10 times and take the majority" — but look at the shape of the answers. The pattern of agreement and disagreement is a behavioral fingerprint of the AI's certainty. Tight consensus means confidence. Scattered answers mean confusion. And — crucially — confident-but-wrong looks different from confident-and-right, once you add the second piece.
The second piece: calibration with a human. Fifty random questions. For each, you've already run the repetitions and ranked the answers by frequency. Now a human spends a few seconds per question checking the top answer. Right or wrong. That's it.
Fifty checks. A few minutes. Not labeling a dataset. Not building training data. Just: did the AI's most popular answer get it right?
From those fifty checks, the framework computes one number.
The reliability level.
94.6% means: for any new question you throw at this system, the AI's top answer is correct with at least 94.6% probability. Not "in our tests" — for any new question. With a mathematical guarantee that holds regardless of what errors the AI makes, regardless of how the data is distributed.
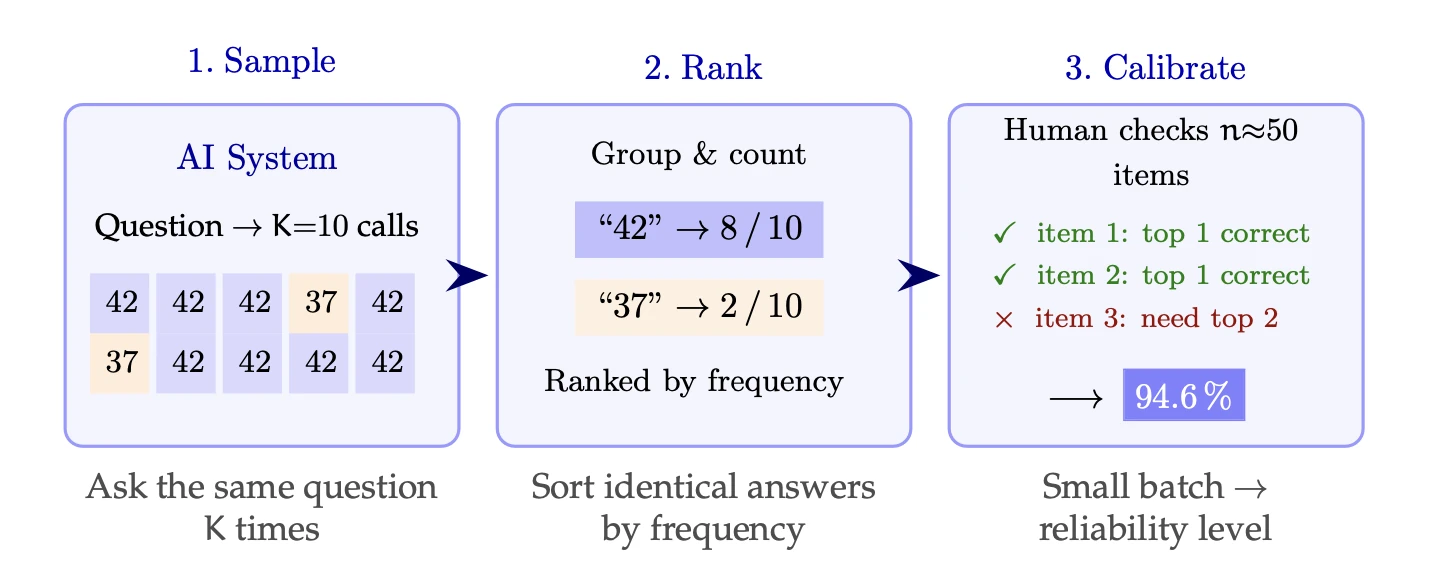
The math behind this is called conformal prediction. It's been in the statistics literature since 2005 but had never been applied this way — to black-box AI systems, using only their external behavior, without any access to model weights or probabilities. That combination is what makes it practical. You don't need to be OpenAI to run this. You need an API key and an afternoon.
What I Didn't Expect
The reliability levels, I expected. I'm a mathematician. Theorems do what theorems do.
What I didn't expect was the visibility.
When the AI is uncertain about a question, the prediction set gets bigger. Instead of one answer, you need the top two. Or the top three. That bigger set isn't a failure — it's information. It's the system making uncertainty visible for the first time.
On easy questions: the set is a singleton. One answer. Ship it.
On hard questions: the set expands. Two or three candidates. Flag it. Have a human glance at it.
On questions the AI genuinely can't solve: the set explodes. The framework doesn't pretend. It says: this model (system or agent) doesn't know (it's just guessing).

That's what Leila needed. Not a 94% accuracy score that hid the page 37 problem. A system that would have flagged that specific report — that summary, not summaries in general — as one where the AI was less certain.
Not "you're mostly healthy." But "you're healthy — except here, and here, and here. Let's look at those specifically."
One is reassuring. The other is useful.
The Honest Numbers
I ran experiments across five benchmarks, five models from three families. No cherry-picking. Here's what I found.
GPT-4.1 earns 94.6% reliability on grade-school math. 96.8% on factual truthfulness. On both, the top answer alone is enough — set size 1. One answer, certified.
Open-weight models hold up. Llama 4 Maverick: 95.4% on math. Mistral Small 24B — a model you can run on your own hardware: 95.4% too. You don't need a closed API for reliable math.
GPT-4.1-nano — the cheapest option — earns 89.8% on math, but only 66.5% on general knowledge. The framework is honest. A weaker model gets a lower number. Not a flattering number. Not a marketing number. A real number.
Code generation is where it gets interesting. GPT-4.1 on HumanEval: 70.7% coverage. Low? Yes — because 26.8% of the problems are genuinely unsolvable for this model. It never produces a correct answer, no matter how many times you ask. But on the problems it can solve, conditional coverage is 96.7%. The framework doesn't hide the capability gap. It separates "the model can't do this" from "the evaluation failed." Different diagnoses. Different actions.
And the cost: a built-in stopping rule — when the AI is confident after a few repetitions, stop early — saves roughly 50% on API calls. Same guarantees. Half the bill.
What This Means for You
Three things.
Use it as a deployment gate. Before anything goes live, run the test. Set a threshold — 90% for automated decisions, 80% for human-assisted workflows. Pass? Ship it. Fail? Fix it or add oversight. No more "the demo looked good." A number. A threshold. A decision you can defend.
Use prediction sets for intelligent routing. Set size 1 → auto-approve. Set size 2-3 → human glance. Set size 4+ → full review. The AI handles what it's confident about. Humans handle what it's not. That's not a limitation — that's a well-designed system.
Use the reliability level to choose between models. GPT-4.1 at 94.6% costs $X per query. An open-weight alternative at 91.2% costs a fraction. How much reliability is worth how much money? Now it's a spreadsheet problem, not a vibes problem.
What This Doesn't Do
I'm not going to oversell this. That would be ironic.
The reliability level is a marginal guarantee — it holds on average across questions, not per individual question. Some hard questions will still get wrong answers. The prediction set flags them, but it's a flag, not a force field. On solvable items, coverage exceeds 93% across every model and benchmark. When it drops below target, it's because the AI can't solve certain problems — and the framework tells you that's why.
The guarantee assumes your deployment data looks like your calibration data. Calibrate on English, deploy on English. If the world shifts, re-calibrate. Every statistical method has this assumption. I'm just not hiding it.
And it requires a human. Fifty checks. A few minutes. But still — a human. The human is what makes the guarantee real. Without the human, you're back to AI grading AI — which is the problem we're trying to solve.
Last week, I wrote about Thomas — the guy who understood why the CRM existed, not just how to click the buttons. The guy who became the most valuable person on his team when 340 Salesforce licenses disappeared overnight.
Thomas's superpower was judgment. He could look at an AI agent's output and say "row 47 doesn't make sense" before anyone else noticed.
The reliability framework is what happens when you take that judgment and give it a mathematical backbone. The human still provides the ground truth — 50 checks, a few seconds each. The math provides the guarantee. The AI provides the output.
Three roles. One system. One number.
I formalized all of this in a paper — the theorems, the experiments, the full validation across five benchmarks and five models. It's on arxiv if you want the math.
We're deploying the framework at PwC now. It works on real systems, not just benchmarks.
But the core idea fits in one line, and it's the line I keep coming back to:
AI will never say "I don't know." But now we can figure out exactly when it should have.
Have a great weekend.
— Charafeddine (CM)