
Mastering Large Language Models: Applications & Optimization on Azure GPU Clusters
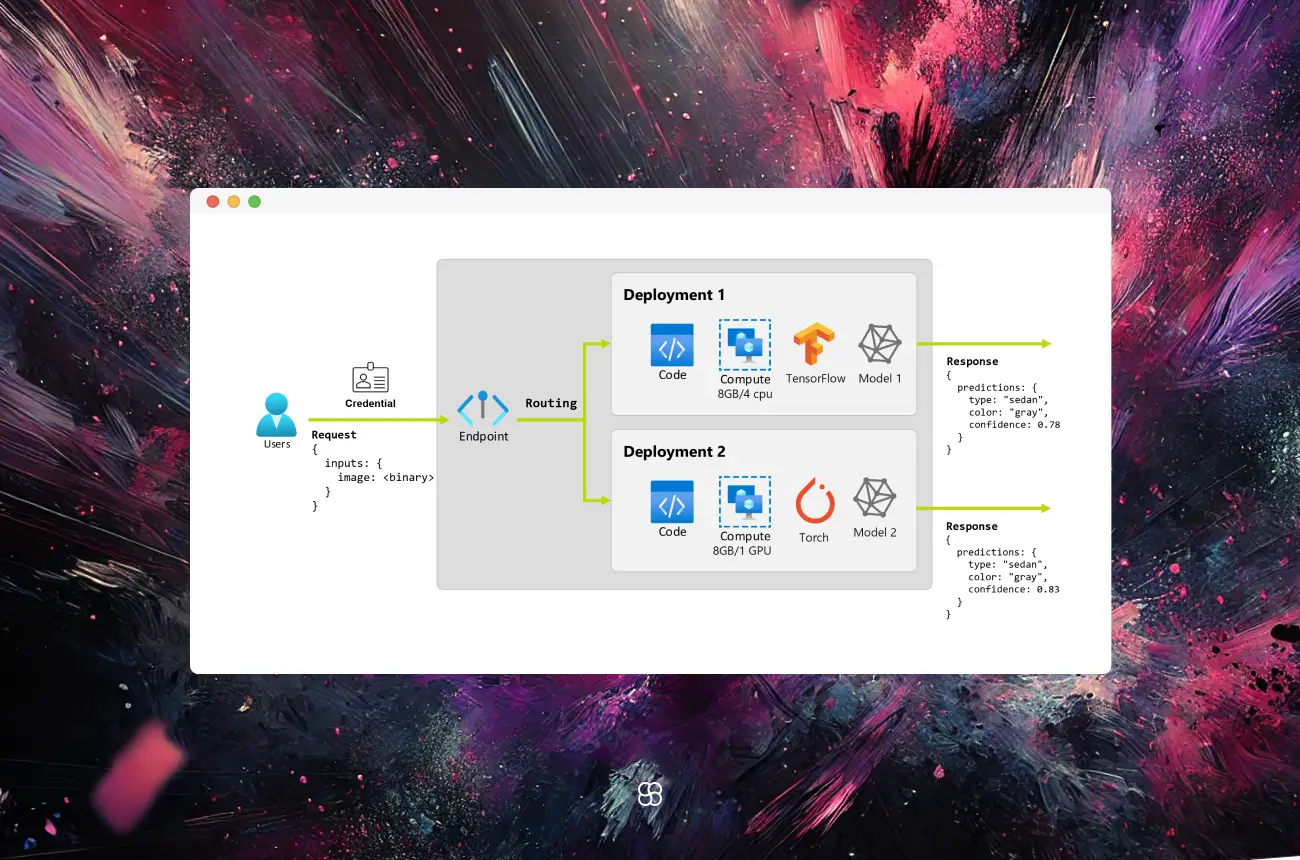
Optimizing large language models (LLMs) on Azure GPU clusters is essential for efficient training and deployment in natural language processing (NLP) applications. Azure provides a robust infrastructure to support the scaling and optimization of LLMs, ensuring high performance and cost-effectiveness. This guide offers a comprehensive approach to setting up and optimizing LLMs on Azure GPU clusters, complete with code snippets and practical insights.
Benefits of Optimizing LLMs on Azure GPU Clusters
- Scalability: Azure's GPU clusters allow for seamless scaling, accommodating the training of models with billions of parameters.
- Performance: Leveraging Azure's high-performance computing resources accelerates training times, enabling faster iterations.
- Cost-Effectiveness: Efficient resource utilization and optimization techniques help in reducing operational costs.
Getting Started with Azure GPU Clusters
Installation and Setup
- Azure Subscription:
Ensure you have an active Azure subscription.
- Azure CLI Installation:
Install the Azure Command-Line Interface (CLI) for managing Azure resources.
- For Ubuntu/Debian:
curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash- For macOS:
brew install azure-cli- Resource Group Creation:
Create a resource group to organize your Azure resources.
az group create --name llm-training-rg --location eastus- Virtual Network Setup:
Set up a virtual network for your GPU cluster.
az network vnet create --resource-group llm-training-rg --name llm-vnet --address-prefix 10.0.0.0/16- Subnet Creation:
Create a subnet within the virtual network.
az network vnet subnet create --resource-group llm-training-rg --vnet-name llm-vnet --name llm-subnet --address-prefix 10.0.0.0/24- Azure Machine Learning Workspace:
Set up an Azure Machine Learning (AML) workspace.
az ml workspace create --name llm-aml-workspace --resource-group llm-training-rg --location eastus- Compute Cluster Creation:
Create a GPU-enabled compute cluster within the AML workspace.
az ml compute create --name gpu-cluster --resource-group llm-training-rg --workspace-name llm-aml-workspace --type AmlCompute --min-instances 0 --max-instances 4 --size Standard_NC6s_v3Building and Optimizing a Simple NLP Agent
Let's walk through building a simple NLP agent using a pre-trained transformer model and optimizing it on Azure's GPU cluster.
- Environment Setup:
Ensure the necessary Python packages are installed.
pip install transformers datasets azure-ai-ml- Initialize the AML Workspace:
Configure the workspace in your Python script or Jupyter notebook.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# Initialize MLClient
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="your-subscription-id",
resource_group_name="llm-training-rg",
workspace_name="llm-aml-workspace"
)- Define the Training Script:
Create a Python script (train.py) for fine-tuning the model.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Load dataset
dataset = load_dataset("imdb")
# Load pre-trained model
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# Define training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=False,
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
)
# Train the model
trainer.train()- Create a Custom Environment:
Define a custom environment in AML to specify dependencies.
from azure.ai.ml.entities import Environment
env = Environment(
name="transformers-env",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
conda_file="environment.yml"
)-
environment.ymlshould include necessary packages:
name: transformers-env
channels:
- conda-forge
dependencies:
- python=3.8
- pip
- pip:
- transformers
- datasets- Submit the Training Job:
Configure and submit the job to the AML compute cluster.
from azure.ai.ml import command
from azure.ai.ml.entities import Job
job = command(
code="./", # location of the training script
command="python train.py",
environment=env,
compute="gpu-cluster",
display_name="bert-finetune-imdb",
experiment_name="nlp-finetuning"
)Submitting the Training Job
With the environment and training script prepared, the next step is to submit the training job to Azure Machine Learning (AML). This process involves configuring the job with the necessary parameters and executing it on the specified compute cluster.
- Define the Command Job:
Utilize the command function from the azure.ai.ml module to specify the details of the training job.
from azure.ai.ml import command
# Define the command job
job = command(
code="./", # Path to the directory containing the training script
command="python train.py", # Command to execute the training script
environment=env, # Environment defined earlier
compute="gpu-cluster", # Name of the compute cluster
display_name="bert-finetune-imdb", # Name of the job
experiment_name="nlp-finetuning" # Name of the experiment
)In this configuration:
codespecifies the directory containing your training script (train.py).commandspecifies the command to run the training script.environmentrefers to the custom environment you defined earlier.computespecifies the compute cluster to use for training.display_nameandexperiment_nameare identifiers for the job and experiment, respectively.
- Submit the Job:
Submit the configured job to the AML workspace and monitor its progress.
# Submit the job
returned_job = ml_client.jobs.create_or_update(job)
# Wait for the job to complete
returned_job.wait_for_completion(show_output=True)After submitting the job, you can monitor its progress in the AML studio or through the SDK. Once the job is complete, the trained model and any outputs will be available in the specified output directory.
Final Thoughts
Optimizing large language models on Azure GPU clusters enables efficient and scalable training for complex NLP tasks. By leveraging Azure's robust infrastructure and services, such as Azure Machine Learning and GPU-enabled compute clusters, you can accelerate the development and deployment of sophisticated language models. This approach not only enhances performance but also provides flexibility and control over the training process, allowing for fine-tuning and optimization tailored to specific application needs.
As you advance, consider exploring distributed training strategies, automated hyperparameter tuning, and integration with other Azure services to further optimize and scale your NLP solutions. Staying updated with Azure's evolving offerings will ensure that you continue to leverage the best tools and practices for your machine learning workflows.
Cohorte Team,
February 4, 2025
