

Business process automation with AI often involves multiple agents (AI systems) that need access to tools and data, and sometimes need to collaborate with each other. Two emerging frameworks address these needs: Anthropic’s Model Context Protocol (MCP) and Google’s Agent-to-Agent (A2A). In simple terms, MCP focuses on connecting AI agents to external tools and context (vertical integration), while A2A focuses on communication between agents themselves (horizontal integration). This article provides a deep dive into both MCP and A2A, comparing their architecture, communication methods, integration capabilities, performance in complex workflows, code examples, and how they can complement each other in automating business processes.
Architectural Overview of MCP and A2A
MCP Architecture: The Model Context Protocol uses a client-server architecture to bridge AI models with data sources and tools An MCP Host (e.g. a chat interface like Claude Desktop or an IDE assistant) contains an MCP Client that manages connections to one or more MCP Servers. Each MCP server exposes a specific integration – for example, a filesystem, database, or API – through a standardized interface. The host (AI agent) can retrieve context or invoke operations via these servers. Think of MCP as a “USB-C port” for AI – a universal plug that lets the AI connect to many peripherals (tools/data sources) in a standard way.
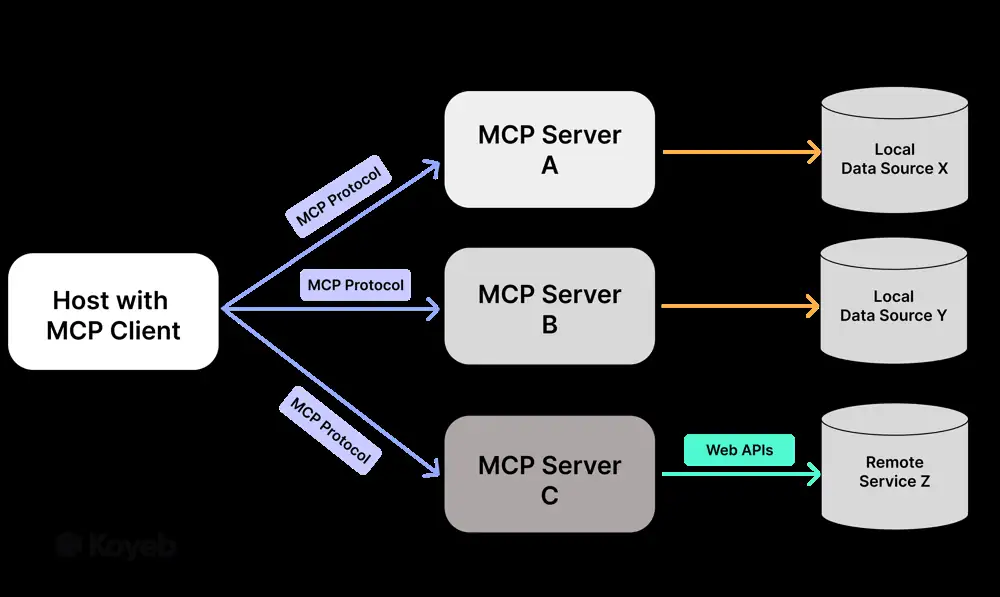
Each MCP server typically offers three kinds of capabilities to the AI agent:
- Tools: Functions or actions the model can invoke (e.g. query an API, send an email). These are model-controlled (the AI can decide to call them).
- Resources: Read-only data or context that can be fetched (files, database records, documents). These are application-controlled – the app or user decides which resources to provide as context.
- Prompts: Pre-defined prompt templates or workflows that guide the AI in specific tasks. These are user-controlled – selected by the user to shape the interaction.
MCP servers advertise their available tools, resources, and prompts, and the MCP client performs a handshake and discovery process to list these capabilities. The host can then make these available to the AI model (for example, by formatting tools as function-call options for the LLM). When the AI needs to use a tool or fetch a resource, the MCP client sends a request to the corresponding server and gets back the result. Communication can occur via Stdio (standard I/O) for local servers or HTTP + Server-Sent Events (SSE) for remote servers, both following a JSON-RPC 2.0 message format. This allows flexible deployment – e.g., running a tool integration as a local subprocess or as a cloud service.
A2A Architecture: Google’s Agent-to-Agent framework is an open protocol for direct agent communication across different platforms and organizationsgithub.comgithub.com. Instead of connecting to tools, an agent in A2A connects to other agents through a standard task-oriented message protocol. Each agent that supports A2A exposes an A2A Server endpoint (usually an HTTP API) and publishes an Agent Card – a JSON metadata file (often at a URL like /.well-known/agent.json) describing the agent’s capabilities (“skills”), API endpoint, and auth requirements. Another agent can act as an A2A Client by discovering this card and then sending task requests to the server.
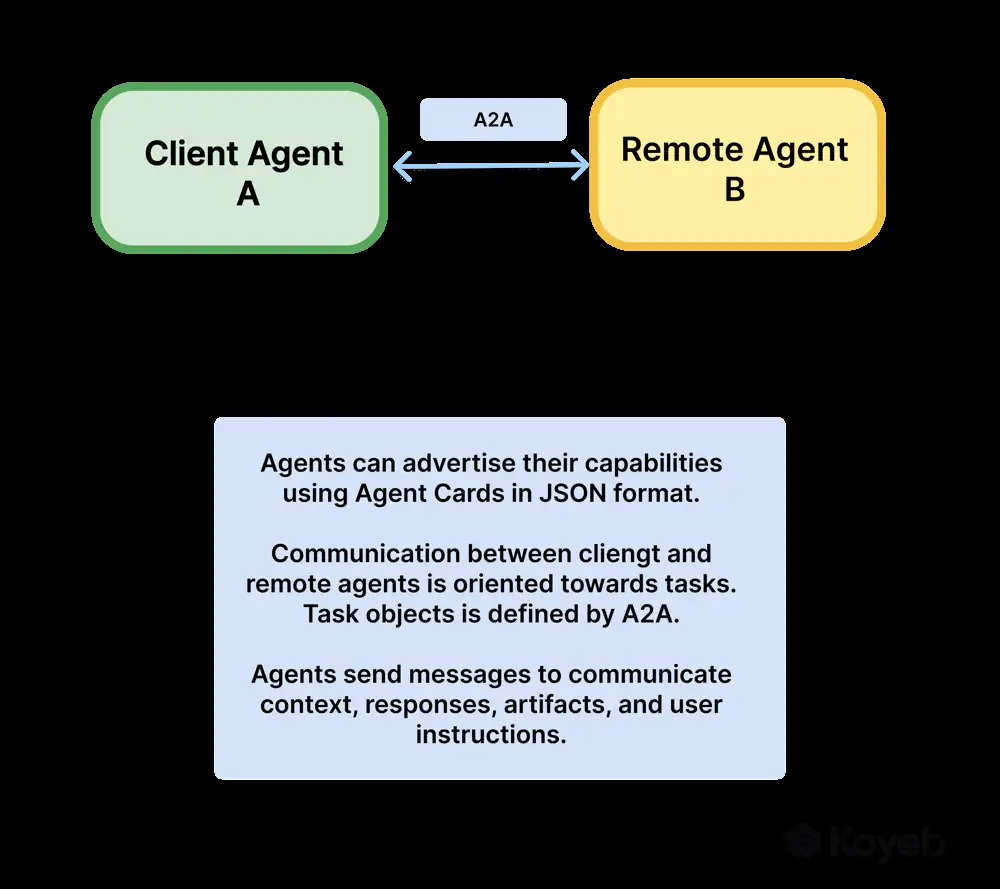
In A2A, all interactions are wrapped in a Task lifecycle. One agent (the client in that interaction) creates a task with a unique ID and an initial message, sending it via a tasks/send request to the other agent (the remote agent). The message typically contains the user’s request or some instruction, packaged into one or more Parts (each part can be text, a file, or structured data). The remote agent processes the task – possibly involving its own reasoning or tool use – and replies with Messages and/or Artifacts. Messages represent the dialogue turns (for example, the agent asking for clarification would send a message with role: "agent" and maybe a question). Artifacts are outputs like files or final results produced during the task. The task has states such as submitted, working, input-required (if the agent needs more info from the user or client agent), completed, etc., which allow for complex, multi-turn workflows.
A2A’s design builds on web standards – it uses HTTP(S) + JSON (JSON-RPC 2.0) for requests, and supports SSE for streaming live updates and webhooks (push notifications) for long-running tasks. This means an agent can stream partial results or status updates back to the caller, or notify when a long job is done, without the caller polling constantly. The protocol also emphasizes capability discovery (via the agent cards) and negotiation of interaction modality – agents can even negotiate how to interact (text, forms, audio, etc.) if needed. Security is considered as well (support for authentication schemes similar to OpenAPI).
Communication, Coordination, and Memory Handling
MCP: Context Injection and Tool Invocation
MCP is fundamentally about providing context and actions to an LLM-based agent. Communication in MCP occurs between the client (in the host/agent) and the server (integration). MCP defines request-response messages for things like listing tools (tools/list), calling a tool (tools/call), reading a resource (resources/read), etc., as well as one-way notifications. Under the hood it follows JSON-RPC 2.0, which includes standard fields for request IDs, method names, params, and error handling. This structured messaging means the AI agent can programmatically query what a tool can do and invoke it through a well-defined interface, rather than relying on brittle prompt strings.
To coordinate with the AI’s reasoning process, many MCP implementations make use of the LLM’s function calling or tool-use paradigm. For example, the OpenAI Agents SDK integrates MCP servers by treating each MCP tool as an available function for the model. At runtime, the agent will automatically call call_tool() on the MCP server when the model decides to use that function. The MCP client handles this call and waits for the server’s response (e.g., the result of a database query), which it then returns to the model.
Context/Memory in MCP: Since LLMs have a limited context window, MCP helps fetch relevant context on demand. Resources serve as an external memory – the agent can retrieve documents, knowledge base entries, or other data via resource URIs (e.g., file:// paths, database keys, etc.). The client or user typically chooses which resources to pull in, ensuring the model gets only the relevant snippets (to avoid overloading context). In some cases, the AI itself might be allowed to select resources or ask for them, but the protocol encourages an app or user to stay in control of context provisioning for safety. For a more agent-driven approach (where the AI can decide to fetch data), developers can expose those data sources as tools instead. For example, rather than automatically reading a huge database, the AI might have a search_db tool it can call with a query – under the hood it returns a piece of data, but it’s treated as a tool invocation (model-controlled) so the AI triggers it only when needed.
MCP does not enforce a particular memory persistence across sessions – that is usually handled by the AI application. However, the MCP ecosystem includes examples of a “Memory” server that provides a knowledge graph or vector store for long-term memory. Such a server can let an agent store and retrieve embeddings or facts, effectively extending the agent’s memory beyond a single context window. Since MCP servers can be written to interface with any backend, developers have created integrations for vector databases like Qdrant and Weaviate to support semantic search as a tool. This means an AI agent could, for instance, call a vector_search tool via MCP to find related information in a vector DB, achieving retrieval-augmented generation (RAG) in a standardized way.
In summary, MCP handles coordination by giving the agent structured access to tools and data. The agent’s core reasoning loop remains within the LLM, but MCP intermediates when the agent needs outside help. The protocol ensures the agent’s requests to tools are linked to responses (through request IDs) and can handle errors gracefully (via JSON-RPC error objects). Multiple MCP servers can be connected simultaneously, but generally the agent will invoke one tool at a time as needed in its chain of thought (the client multiplexes requests to the correct server).
A2A: Agent Collaboration and Task Management
A2A handles coordination at a higher level – agents coordinating with other agents. Communication in A2A is centered on the Task model. When Agent A needs help from Agent B, Agent A (as a client) sends a tasks/send request containing a new task ID and an initial message. The message could be something like: “User asks: What are the sales figures for last quarter?” if Agent A is delegating to a specialized “analytics agent”, for example. Agent B, upon receiving this, will generate a response (or series of messages) trying to fulfill the task.
During a task’s lifecycle, agents exchange Messages that carry the conversation forward. Each message has a role (either "user" or "agent" from the perspective of the task). For instance, Agent B might send back a message saying, “I can retrieve the data. Do you want it broken down by region?” – marked as role "agent" asking the user (Agent A, acting on the user’s behalf) for input. This would put the task in an input-required state. Then Agent A can send another tasks/send with the additional info (e.g., “Yes, breakdown by region.”). This back-and-forth continues until Agent B signals completion with a final answer or result.
One powerful aspect of A2A is that agents do not share their internal chain-of-thought or memory – they communicate only via these structured messages and artifacts. Google describes this as “opaque execution” – each agent remains a black box in terms of how it computes the answer. They only share the necessary inputs/outputs. This ensures that, for example, proprietary reasoning or confidential data an agent has in memory is not directly exposed, unless deliberately sent as a message or artifact. It also means each agent can have its own tools or context (perhaps using MCP internally!) and only the end result is exchanged. In other words, A2A treats each agent almost like an autonomous web service – one that can chat and exchange files – rather than merging their internals.
The A2A protocol supports multiple concurrency and long-running coordination patterns. For long tasks, instead of a simple request/response, the Server-Sent Events (SSE) channel allows the remote agent to stream TaskStatusUpdate events (e.g., “20% complete”) and TaskArtifactUpdate events (intermediate outputs) to the client. If a task might take a very long time (say hours or days, with a human eventually providing input), A2A servers can also use push notifications – the client can set a webhook where it wants updates, and the server will POST updates or results there, so the agents can disconnect and not hold the HTTP connection open. This design acknowledges that in enterprise workflows, an agent might delegate a task that involves waiting for human approval or an external process; A2A can handle that reliably by marking the task state as working or waiting and resuming when ready.
Coordination and roles: In any A2A interaction, one agent is initiating (client role) and the other is fulfilling (server role). But these roles are flexible and can switch. Agent A might call Agent B for one task, and later Agent B could call Agent A (if Agent A exposes A2A server capabilities) for a different task. This allows peer-to-peer collaboration. In practice, for clarity, many architectures will have a primary orchestrator agent that delegates subtasks to specialist agents. But A2A doesn’t enforce a hierarchy; any agent that knows another’s endpoint and has permission can send tasks.
Memory in A2A: Each agent keeps its own memory of tasks it is handling. The A2A protocol itself doesn’t specify how an agent should remember context, only that within a task, the history of messages is logically tracked (the agent can infer context from prior messages in that task’s thread). An agent implementation could store the conversation history of a task ID and use it when generating new responses. Because tasks have IDs, even if communication is intermittent, an agent can look up the state (messages and artifacts so far) of that task and continue. This is crucial for reliability – if a network hiccup occurs, the client can poll the tasks/status or simply retry tasks/send with the same task ID and last message, and the server knows it’s part of an ongoing interaction.
The isolation of memory per agent means if broader shared memory is needed, it has to be through explicit communication. For example, if Agent A wants Agent B to use some data A has, A must send it as part of the task (maybe as a FilePart or DataPart in a message). This clear delineation can actually aid security and debugging, since all cross-agent info exchange is visible in the task messages.
In summary, A2A provides a structured yet flexible way for agents to coordinate on tasks without merging their internal states. Agents coordinate by negotiating tasks: the client agent specifies what it wants, the remote agent can ask for clarifications or provide partial results, and ultimately returns a completion or failure. All of this happens with standardized message types and state transitions that any A2A-compliant agent can understand.
Integration and Extensibility with LLMs and Tools
Integration with LLMs and Agent Frameworks
Both MCP and A2A are designed to be model-agnostic and framework-agnostic, meaning they can work with various large language models (LLMs) or agent frameworks, as long as those can interface with their protocols.
- MCP Integration: Since MCP standardizes the way context and tools are provided to an AI, it allows developers to switch out the underlying LLM or provider without changing how they connect to data. For instance, you could use OpenAI’s GPT-4 today and Anthropic’s Claude tomorrow, and as long as your app supports MCP, the way you fetch documents or call APIs remains the same. Anthropic built MCP initially to integrate Claude with external data in a secure way, and they open-sourced it to work with any model. Indeed, OpenAI has adopted MCP in their Agents SDK, calling it “a standardized way to connect AI models to different data sources and tools”. OpenAI’s implementation provides classes like
MCPServerStdioandMCPServerSseto easily attach MCP servers (tools) to an agent, and will automatically handle thelist_toolsandcall_toolworkflow with the LLM. There are SDKs for multiple languages (Python, TypeScript/JS, Java, Kotlin, C#), making it easy to integrate MCP in different environments – from web apps to desktop apps. - Importantly, MCP’s design aligns well with the function calling interfaces now common in LLMs (like OpenAI Functions or Google’s Toolformer-style APIs). If an LLM supports function calls, each MCP tool can be registered as a function with the tool’s JSON schema for inputs. The model can then decide to invoke it, and the agent runtime (client) will route that to the MCP server. Even without native function calling, a developer can implement a prompt strategy (like ReACT or a custom format) where the model outputs a special token to indicate tool use, and the client intercepts that to call the MCP server. Thus, MCP is extensible to essentially any LLM-based agent.
- A2A Integration: A2A is an open protocol specification rather than a specific implementation, which means any agent framework can implement the A2A client/server interface. Google kickstarted this effort with their Agent Development Kit (ADK), an open-source toolkit that natively supports A2A and even can act as an MCP client. But beyond ADK, the A2A GitHub repo provides sample integrations for several popular agent frameworks and libraries: LangChain/LangGraph, LlamaIndex, Marvin, Semantic Kernel, Crew (CrewAI) are mentioned as early examples or samples. The community has also created wrapper libraries (for example, a Python
a2apackage) to simplify using A2A in custom agents. With A2A using plain HTTP+JSON, integrating it is similar to working with any REST API or gRPC – many languages can consume it. Agents just need to be able to send HTTP requests and handle JSON responses (plus SSE streams for updates). - One key aspect is that A2A is vendor-neutral. An agent running on Google’s PaLM 2 or Gemini via the ADK can talk to another agent running on OpenAI GPT-4 via LangChain, or to an open-source LLM agent running locally – as long as each implements the protocol. This opens up flexibility to mix and match AI services. For example, a company could use a powerful but expensive LLM for a complex reasoning agent, and have it delegate straightforward lookup tasks to a cheaper local LLM agent – or vice versa – coordinating via A2A.
- For LLM integration specifically, the A2A messages carry content in a model-agnostic way. Parts of type
TextPartare just plaintext, which any LLM can generate or consume. If an agent wants to support richer modalities (images, etc.), it can includeFilePart(with a URI or encoded file) – an image-oriented agent could handle that, whereas a text-only agent might ignore or decline it. Thus, A2A doesn’t require special model capabilities; it’s on the agent implementation to decide what to do with each part. Capability discovery via the Agent Card helps here: an agent can advertise what content types it can handle (for instance, an Agent Card might list that the agent can handleaudioinput or producevideooutput, etc.). This way a client agent can pick an appropriate partner for a task (e.g., choose an agent that has a “GenerateReport” skill for a document generation task).
Tool and External System Extensibility
- Extending MCP with New Tools/Data: MCP was explicitly designed to make adding new integrations easy and standardized. Developers create new MCP servers for each data source or service. Anthropic and others have already built a catalog of MCP servers for common tools: e.g., servers for Slack (messaging), Google Drive (files search), GitHub/GitLab (repo operations), various databases (Postgres, SQLite), web browsers (Puppeteer automation), and even cloud services like AWS and Stripe. Each server is like a microservice exposing a narrow set of capabilities. Writing an MCP server can be as simple as writing a few functions with a decorator. For example, the MCP Python SDK allows developers to define a tool or resource with a Python function, using decorators such as
@mcp.tool()or@mcp.resource(). The SDK handles registering it under the hood so that when the client callstools/list, the function appears as an available tool, and whentools/callis invoked, it executes the function. - Because MCP servers communicate via a defined schema (JSON for inputs/outputs), they are inherently language-agnostic on the wire. You could implement a server in Node.js or Go (using the JSON spec) and the client (written in Python, for instance) can still use it. The transport layer abstraction means you could even host an MCP server as a web service at a URL – as of the MCP spec, SSE over HTTP is supported for remote servers. This means third parties or internal teams can host useful MCP services (e.g., a “CRM server” that provides tools to create or read customer records via an API) and any MCP-compatible agent can plug into it. It’s similar to how in the enterprise, one might have many microservices – MCP provides a uniform API contract for AI-related services.
- Extensibility to new LLM tools is also straightforward: if tomorrow a new kind of AI tool is invented (say, controlling a robotic process), one can write an MCP server for it exposing the necessary commands. The AI agent doesn’t need a custom integration, it just needs to know the server’s address and then it can discover the new tool. This decoupling is powerful for evolving AI systems – as one blog noted, “With the right set of MCP servers, users can turn every MCP client into an ‘everything app’”.
- Extending A2A with New Agents: In A2A, adding extensibility means introducing new agents with new capabilities into the ecosystem. Let’s say an enterprise has an agent that specializes in financial analysis, and another that specializes in customer support knowledge base lookup. If one now wants a marketing analytics agent, they can build or deploy one and publish its Agent Card. Other agents can discover it and start utilizing its skills. The key is that each agent can describe its skills in the Agent Card (for example, the marketing agent’s card might list a skill like “generate_campaign_report” with an input schema of required data). Because the protocol is open, any organization or vendor can create an agent and register it to be callable. Google’s vision is that agents from different vendors form a interoperable network, much like services on the internet do.
- Integrating tools in A2A is indirect – A2A does not directly provide tools to an agent, but if an agent has tools (perhaps via MCP or native integration), it can use them internally to fulfill tasks. For example, if Agent B in an A2A conversation needs to fetch some data, it might internally call its database or API integration, then return the result in an artifact to Agent A. From Agent A’s perspective, it didn’t need to know how B got the data, just that B had the “skill” to provide it. This encourages specialization: one agent might effectively wrap a suite of MCP tools and present a higher-level capability via A2A.
- A concrete scenario of extensibility could be seen in a multi-department business workflow: Imagine a “Finance Agent” and an “HR Agent” in a company. The Finance Agent might have MCP tools connected to the finance databases and APIs (invoices, ledgers), while the HR Agent has tools for employee database and payroll system. If they both implement A2A, a complex task like onboarding a new employee (which touches both HR and Finance data) could be automated by these agents collaborating: the HR Agent could call the Finance Agent via A2A to setup payroll accounts for the new hire. Neither agent needs direct access to the other’s databases – they request each other’s services through tasks. This modularity and clear separation of concerns is analogous to microservices in software architecture, but for AI agents.
- Community and Cross-Compatibility: Google announced A2A with a consortium of over 50 partners, including major enterprise software players and AI companies. Many expressed support, seeing it as a way to standardize multi-agent workflows much like APIs standardized web services. For instance, Cohere (an AI provider) highlighted how A2A enables “seamless, trusted collaboration—even in air-gapped environments”. This indicates that even closed environments can use A2A within an intranet, for example, to let agents talk without exposing data outside. On the other hand, Anthropic and OpenAI were notably not listed among initial partners (likely because they have their own focuses), though Anthropic’s MCP is explicitly complementary. The A2A spec is open and could be adopted by them or others in the future for interoperability.
Performance, Flexibility, and Reliability in Complex Workflows
Long-Running Workflows and Multi-Agent Environments
In practical business processes, tasks might be complex, involving many steps or waiting for events. Let’s compare how MCP and A2A handle these scenarios:
- MCP in Long Workflows: MCP itself is stateless between individual requests – it’s more like a library of tools the agent can use at any point. For a long workflow (say, processing a loan application involving multiple steps like document upload, verification, approval), the orchestration logic would typically live in the agent’s design (or prompt chain), not in MCP. However, MCP’s prompt templates feature can help guide multi-step workflows. For example, a server could provide a prompt called
"document-review-workflow"which chains multiple interactions (like first summarizing a document, then extracting specific data). The agent (or user) can select this prompt, which ensures the LLM follows a predefined multi-step process. Still, MCP calls happen one at a time as the model decides to use a tool or needs context. - In terms of long-running actions, most MCP tool calls are expected to be relatively short (e.g., execute an API call and return data). If a tool needs to do something time-consuming, the current MCP implementation would have the agent wait for the result (since it’s a call-response). There isn’t an explicit async update mechanism in MCP at the protocol level beyond perhaps chunked responses or splitting a task into multiple tool calls. That said, nothing stops a developer from designing a tool that initiates a background job and immediately returns a ticket or ID, which the agent can later use to poll via another tool call – but that’s a custom solution.
- Reliability and Robustness: Because MCP connections can be local, they can be very fast and reliable (no network needed for stdio). Even remote SSE connections are one-to-one and relatively straightforward. MCP uses JSON-RPC which is a mature pattern with clear error semantics. If a tool fails or an error occurs (e.g., API error, file not found), the MCP server can return a JSON-RPC error which the client will surface to the AI or user. The agent designer can then decide how the AI should handle errors (perhaps the AI can attempt a different approach or ask the user for guidance). Also, since MCP servers are separate processes, a crash or issue in one tool doesn’t take down the whole agent – the agent could even disconnect from that server and continue using others.
- In multi-agent environments, MCP doesn’t directly handle agent-to-agent, but you might have multiple agents each with their own MCP integrations. If those agents need to collaborate, that’s where A2A comes in.
- A2A in Long Workflows: A2A was built with long-running and asynchronous tasks in mind. It explicitly supports keeping tasks open and allowing intermittent communication. For example, consider a sales workflow where an AI agent processes a purchase order: it might have to wait for stock confirmation from a warehouse agent and a credit approval from a finance agent. Using A2A, the sales agent could initiate tasks with both the warehouse and finance agents. If the warehouse agent needs 30 minutes to do a physical inventory check (maybe via IoT systems), it can put the task in
workingstate and later send a push notification when done. Meanwhile, the finance agent might quickly respond that credit is approved. The sales agent can combine these when both complete. This non-blocking, event-driven style is crucial for enterprise workflows that involve parallel processes or human approvals. - A2A’s use of SSE for real-time updates ensures that if an agent is actively waiting, it gets timely feedback. For instance, an agent could start a data analysis task on another agent and subscribe for streaming results – as soon as the first few results are ready, it receives them and could even start acting on them (pipelining the process). The protocol’s support for a variety of patterns (synchronous request/response, async with polling, async with SSE, async with webhooks) covers the spectrum of needs. This flexibility is a big advantage when building multi-agent systems that must be robust. Agents can recover from disconnects (they can reconnect and resume a task by its ID), and if an agent crashes, the task will eventually time-out or fail, and the calling agent can handle that gracefully.
- Enterprise reliability: The A2A design borrowed concepts from enterprise messaging. By not requiring shared memory and by leveraging web standards, it makes it easier to deploy agents across different infrastructure. Authentication and authorization are built-in (the Agent Card can specify what auth is needed, e.g., an API key or OAuth token to call the agent). This means in a business setting, an agent could safely expose an endpoint for others to use, secured by familiar methods (similar to securing a REST API). Tracing and audit logs can also be inserted at this layer – since every task request/response is a HTTP call with a defined schema, it’s feasible to log them for monitoring.
- Additionally, A2A is modality-agnostic, supporting not just text but also binary data streams (for audio/video). In a long-running process like a live meeting scheduling agent, one agent could stream audio to another for transcription while they negotiate meeting times, all in one A2A task. This has performance implications (streaming large data), but SSE is generally efficient for that, and if needed, agents can pass around URLs to larger files (so the actual file transfer might be out-of-band via a file server).
Scalability: A2A tasks could be handled by agents that scale horizontally. For example, one could imagine an A2A “agent” actually being a scalable cloud service with multiple instances behind a load balancer all able to handle tasks/send for the same agent identity. Because tasks have IDs and the protocol is stateless between calls (aside from SSE streams tied to a client connection), a backend service can route or distribute tasks as needed. This could allow an agent service to handle many concurrent requests from many other agents – important in a scenario where, say, a very popular “calendar scheduling agent” is used by hundreds of other personal assistant agents.
In contrast, MCP’s scaling is more about how many servers and tools one agent can juggle. Typically one agent (one user’s session) would not connect to an extremely high number of MCP servers at once – it might select a handful relevant to the user’s request. Each MCP server is relatively lightweight (many are just stateless wrappers around an API). If a particular tool needs to handle heavy load (like many file searches), one could deploy multiple instances of that MCP server and have different agents use different instances, but that’s managed at application level, not by MCP itself.
Performance and Flexibility Considerations
Performance: MCP calls are usually fast, as they are direct function calls or local network calls – adding maybe a few tens of milliseconds overhead to what the raw operation would take. The benefit is that the model doesn’t need to handle large outputs in its context window – e.g., instead of reading a whole PDF in the prompt, the agent can call an MCP tool that returns a summary or relevant section of the PDF. This can dramatically improve the practical performance of an AI solution by focusing the model on just the needed data. Also, MCP allows binary data handling for resources (it can transfer files, images, etc.), which means an agent can, for instance, retrieve an image via MCP and then pass a reference of it to an image analysis model, rather than trying to encode image data in text.
For A2A, the overhead is the HTTP call and JSON serialization, which in most cases is negligible compared to the time the AI spends thinking or the external systems take to act. However, if agents chat back and forth a lot, those milliseconds can add up. It’s expected that agents will have relatively high-level exchanges (not every single thought, but rather larger chunks of reasoning or info). Also, because A2A can stream, the latency for first response can be low – an agent can start transmitting an answer as soon as it begins formulating it, akin to how a large language model streams its answer token by token.
One must also consider failure modes: In MCP, if a tool fails or returns nothing useful, the agent might have to try alternative strategies (if programmed to do so) or ask the user for help. In A2A, if a remote agent fails to complete a task, it will send a failed status. The client agent should be prepared to either retry (maybe with a different agent) or report the failure. Both protocols thus require developers to plan for imperfect outputs, but they make it easier to catch those – MCP with error returns, A2A with task states.
Flexibility and Vendor Lock-in: MCP and A2A both aim to prevent lock-in to a single AI vendor. MCP allows switching out the LLM or switching out the integrated tools (e.g., swap a proprietary database for another, and just change the MCP server implementation). A2A allows mixing agents from different sources – e.g., a company could use a document analysis agent from Vendor X and an email drafting agent from Vendor Y and have them talk. This is particularly useful in business automation, where one vendor might not provide all capabilities. For example, an insurance company might use a specialized underwriting agent from a niche provider, but use a general customer-service agent from a big provider; A2A can let them collaborate on a claim process.
Security and Reliability: Both protocols acknowledge security. MCP ensures that data stays where it should – e.g., an MCP server that reads local files can enforce access controls and never send data externally except to the requesting client. The Anthropic introduction emphasized “securing your data within your infrastructure” as a goal This means an enterprise can deploy MCP servers behind their firewall, connect an AI model to them, and the model can answer questions about internal data without that data ever leaving the premises in raw form. A2A emphasizes secure auth and even mentions support for “enterprise-grade authentication... with parity to OpenAPI’s schemes” – likely meaning API keys, OAuth, etc., plus possible integration with existing identity systems. This allows agents in different orgs to safely work together (if permitted), or to safely prevent unauthorized agents from connecting.
From a reliability standpoint, one could use standard techniques like retries for transient failures in both MCP and A2A. The idempotency of certain operations (like reading a resource, or asking an agent a question) helps – doing it twice usually has the same effect as once (except for side-effectful tools).
Code Snippets for Typical Business Use Cases
To make these concepts concrete, let’s look at how one might use MCP and A2A in code for some business-oriented scenarios. These are simplified examples for illustration:
Example 1: Customer Onboarding with MCP Tools
Imagine an AI agent that automates parts of customer onboarding. It needs to: (a) verify a user’s identity document, (b) create a new record in the CRM database, and (c) send a welcome message on Slack.
Using MCP, we can equip the agent with three tools via servers: one for an ID verification API, one for database access, and one for Slack messaging. Below is pseudocode illustrating how an agent (using an SDK similar to OpenAI’s Agents or a custom client) might set this up and use it:
# Pseudocode: Setting up MCP servers for the agent
from mcp import MCPServerSse, MCPServerStdio
# Connect to an ID Verification API MCP server (remote via HTTP+SSE)
id_verify_server = MCPServerSse(url="https://mcp.mycompany.com/id-verify")
# Connect to a local SQLite database MCP server (running as subprocess via stdio)
db_server = MCPServerStdio(command="python", args=["db_mcp_server.py"])
# Connect to a Slack MCP server (could be remote or local)
slack_server = MCPServerSse(url="https://mcp.mycompany.com/slack")
# Assume agent framework allows adding these servers
agent.add_mcp_server(id_verify_server)
agent.add_mcp_server(db_server)
agent.add_mcp_server(slack_server)
# Now the agent's LLM is aware of tools: e.g., "verify_id", "create_user_record", "send_slack_message"
result = agent.run("""
Onboard new customer John Doe with ID document 'johndoe_id.png'.
- Verify the ID.
- Create their account in the CRM.
- Send them a Slack welcome message.
""")
print(result)In this flow, the agent receives an instruction (could be from a user or triggered by an event). Through MCP, it has the following tools available (discovered via tools/list):
verify_id(image_path): provided by the ID verification server (calls an external ID check API).create_user_record(name, details): provided by the DB server (inserts a row into a SQLite or actual CRM via API).send_slack_message(user, message): provided by the Slack server (uses Slack API).
When agent.run() executes, the LLM will likely plan something like: First call verify_id on 'johndoe_id.png'. If successful, call create_user_record. Then call send_slack_message. Thanks to MCP, each of those calls is made via call_tool under the hood. The agent’s code waits for each to complete and feeds the results back into the LLM’s context (or the LLM might chain function calls autonomously, depending on the agent framework’s capabilities). Finally, the agent produces a summary or confirmation, which might be printed or sent back to a user interface. This approach cleanly separates the process: the AI handles decision-making and conversation, while MCP servers handle actual data operations with the company’s systems.
Example 2: Document Processing and Analysis with MCP and Vector DB
Consider an agent that can answer questions about company policy documents. The documents are stored as PDFs. A typical RAG (Retrieval-Augmented Generation) pipeline would involve reading PDFs, indexing embeddings in a vector database, and querying that. With MCP, we can modularize this:
- Use a Filesystem MCP server to treat PDF files as resources.
- Use a Vector DB MCP server (say, Qdrant or Weaviate, from the official integrations) as a tool for semantic search.
- Possibly a Text extraction tool (if PDF needs OCR or text extraction, although one could pre-index offline).
A snippet of how an agent might utilize this:
# Connect to a filesystem server and a Qdrant (vector search) server
fs_server = MCPServerStdio(command="npx", args=["-y", "@modelcontextprotocol/server-filesystem", "--root", "/policies"])
vector_server = MCPServerSse(url="http://localhost:8000") # assume a Qdrant MCP server running
agent.add_mcp_server(fs_server)
agent.add_mcp_server(vector_server)
# Ask a question that requires document retrieval
question = "What is our company policy on remote work and home office setup?"
answer = agent.run(question)Here’s what happens internally:
- The agent gets the user’s question. The LLM on its own might not know the answer (it’s specific to company policy).
- The agent’s toolkit includes something like
search_documents(query)from the vector DB server. The LLM decides to invoke this tool with the query “remote work home office policy”. The MCP client sends that to the vector server, which performs a similarity search over embeddings of all policy docs and returns, say, the top 3 relevant chunks of text as a resource or text output. - The LLM receives those chunks (the MCP client could insert them into the prompt as additional context or the model might have function return handling to add it).
- Now with relevant excerpts, the LLM composes a final answer about the policy (e.g., “The company allows remote work up to 3 days a week and will reimburse home office equipment up to $500” – citing from the docs).
- If the LLM needs to see the full document, it could use a filesystem resource like
file:///policies/RemoteWorkPolicy.pdf. The filesystem server would return the text content (if allowed) or a summary if it’s large.
This example shows how MCP allows on-demand retrieval and tool use without hardcoding a complex pipeline. The agent builder simply plugged in two servers and the model strategy (possibly via prompt engineering or few-shot examples) handles the rest.
Example 3: Sales Workflow with Multi-Agent (A2A)
For a scenario using A2A, let’s imagine a sales process where multiple specialized agents collaborate:
- Sales Assistant Agent: Deals with the customer, gathers requirements.
- Inventory Agent: Checks product availability in warehouses.
- Invoicing Agent: Generates invoices and payment links.
Using A2A, the Sales Assistant (SA) agent can dynamically delegate tasks. Suppose a customer asks, “Can I get 100 units of product X by next week, and what would it cost?” The SA agent might not have all the info, so it uses A2A to involve the others:
Agent Discovery: The SA agent knows (perhaps via configuration or a registry) the Agent Card URLs for Inventory and Invoicing agents, or it knows how to search for an agent with a certain skill. Let’s assume it has them. The cards would contain info like Inventory Agent’s endpoint and that it has a skill check_stock(product, quantity, date), and Invoicing Agent has generate_quote(product, quantity).
Task delegation using A2A (pseudo-code):
import a2a # hypothetical library for A2A
# Initialize A2A clients for each remote agent using their Agent Card URLs
inventory_client = a2a.Client(agent_card_url="https://inventory.example.com/.well-known/agent.json")
invoice_client = a2a.Client(agent_card_url="https://finance.example.com/.well-known/agent.json")
# 1. Check inventory availability by asking Inventory Agent
task_id = "task-001"
request = {
"taskId": task_id,
"message": {
"role": "user",
"parts": [ { "type": "TextPart", "text": "Check availability of 100 units of Product X by 2025-05-15" } ]
}
}
response = inventory_client.send_task(request) # sends tasks/send to Inventory agent
if response.get('state') == 'input-required':
# The inventory agent might ask something (e.g., "Which warehouse?").
followup_message = ... # compose answer as needed
inventory_client.send_task({
"taskId": task_id,
"message": { "role": "user", "parts": [ { "type": "TextPart", "text": followup_message } ] }
})
# Poll or wait for completion (could also use subscribe for SSE)
status = inventory_client.get_status(task_id)
if status['state'] == 'completed':
available = status['result']['parts'][0]['text'] # e.g., "Available: 100 units by 2025-05-10 from Warehouse A"
else:
# handle failure or no availability
available = "not available"
# 2. Get price quote from Invoicing Agent
quote_task = "task-002"
quote_req = {
"taskId": quote_task,
"message": {
"role": "user",
"parts": [ { "type": "TextPart", "text": "Generate price quote for 100 units of Product X" } ]
}
}
quote_response = invoice_client.send_task(quote_req)
quote_status = invoice_client.get_status(quote_task)
price_quote = quote_status['result']['parts'][0]['text'] # e.g., "$5000 with delivery in 7 days"
# 3. Combine results in Sales Assistant's response to customer
if "Available" in available:
final_answer = f"Yes, we can supply 100 units by next week. {price_quote}."
else:
final_answer = "Sorry, we cannot fulfill that order by the requested date."This pseudocode demonstrates an agent orchestrator pattern using A2A. The Sales Assistant agent uses two A2A clients to communicate with the Inventory and Invoicing agents as needed. The actual A2A calls (via send_task and get_status) under the hood construct the proper HTTP requests per the A2A spec (including the JSON structure for messages, etc.). In a real implementation, the SA agent would incorporate this logic into its reasoning: it would ask inventory, maybe wait for a response (perhaps using SSE callbacks rather than polling in a tight loop), then ask finance, then reply to the user.
Notably, all agents remain decoupled:
- The Inventory Agent might itself be using MCP to check various databases for stock, but the Sales Assistant doesn’t care – it just sees a skill and gets a textual answer about availability.
- The Invoicing Agent might be connected to an ERP system to calculate pricing.
- Each agent can scale or be updated independently (e.g., if the company changes how quotes are calculated, they update the Invoicing agent only).
Example 4: Hybrid MCP + A2A in an IT Support Workflow
To illustrate how MCP and A2A together can form a hybrid architecture, consider an IT support chatbot in a large organization. This chatbot is the frontline agent users interact with. Behind the scenes:
- It uses MCP to access tools: e.g., a knowledge base search tool, a ticketing system API tool (to create or update support tickets), and a diagnostic script runner tool.
- It uses A2A to escalate or consult specialized agents: e.g., a Network Troubleshooting Agent or a Hardware Inventory Agent if the issue requires deep knowledge in those areas.
Workflow: A user asks the chatbot, “I cannot connect to the VPN.” The chatbot tries its MCP tools: searches KB articles for “VPN issues” (via a vector search tool), maybe runs a network diagnostics script (via a tool that pings the VPN server). Suppose it finds some info but not enough. It then uses A2A to consult the Network Agent, sending a task: “User cannot connect to VPN. We tried basic diagnostics. What could be the problem?” The Network Agent, which is a separate system (perhaps run by the network team), has skills and data to analyze this. It may ask via A2A for additional info (the chatbot can forward log snippets via artifacts). Ultimately, the Network Agent responds that “There is an outage on VPN server cluster 3, ETA 2 hours to fix.” The chatbot then uses its Slack MCP server to post an update in the IT alerts channel, and finally tells the user the cause and ETA.
This hybrid use shows MCP and A2A are complementary: MCP provides the tools and data integration for individual agent actions, while A2A provides the glue for agent-to-agent collaboration. As one analysis succinctly put it: “A2A is API for agents and MCP is API for tools.” In practice, advanced AI solutions will likely employ both. Google’s ADK example actually demonstrated this: using MCP for tool use and A2A for multi-agent comms in one application.
Early Adopters, Community Insights, and Outlook
Both MCP and A2A are very new (late 2024/early 2025 releases), but they have garnered significant attention:
- MCP Adoption: Anthropic integrated MCP into Claude from the get-go (Claude Desktop supports MCP servers natively). Early adopters like Block (formerly Square) and Apollo integrated MCP into their systems. Several developer tool companies – Zed (code editor), Replit, Codeium, Sourcegraph – have experimented with MCP to augment their AI coding features. This indicates MCP’s usefulness in providing context (like codebase knowledge) to coding assistants. OpenAI’s public endorsement of MCP in their Agents SDK is a big signal of support. There is also a growing open-source community contributing MCP servers (the official repo has many community-contributed integrations). One example is the Memory server which provides a long-term memory store via a knowledge graph, contributed to help agents remember information over time. On social platforms, developers have described MCP as a game-changer to avoid writing boilerplate code for each tool<sup>🔗</sup>. The metaphor “USB for AI” is frequently cited – implying people see it as a needed standard.
- A2A Adoption: Google announced A2A at Google Cloud Next ‘25 with a host of partners. Big enterprise tech companies like Accenture, Cognizant, Confluent, Elastic, Salesforce, ServiceNow (and many more) voiced support, often with quotes about enabling “collaborative agent ecosystems” and “interoperable AI systems”. This shows that industry players foresee a need for different AI agents (perhaps one from ServiceNow for IT automation, one from Salesforce for CRM, etc.) to interoperate for end-to-end workflows. There’s excitement on forums like Reddit, where developers noted they plan to replace proprietary communication hacks (like custom gRPC between agents) with A2A for standardization<sup>🔗</sup>.
- However, the adoption of A2A may hinge on how widely agent frameworks implement it. Google’s own ADK and partners’ platforms will push it forward. There are already community-built tools like Python A2A libraries that wrap the API to make it easier to use (e.g., handling SSE, etc.). Since A2A is open, even those not partnering with Google can implement it. One can imagine open-source AI platforms adding A2A compatibility such that, for example, a LangChain agent could register an Agent Card and accept A2A tasks from outside.
- Complement or Competition? While Google explicitly states “A2A complements Anthropic's MCP”, some observers have speculated on overlap. Solomon Hykes (Docker’s founder) remarked that tools are becoming more agent-like and agents rely on tools, potentially blurring the line. He suggested there could be a “tug of war” for developer mindshare if one protocol tries to subsume the other. As of now, though, each addresses a distinct layer of the stack. A2A isn’t trying to let agents query databases directly – that’s what MCP is for. And MCP isn’t meant for two agents negotiating a plan – that’s squarely A2A’s domain. Developers building complex AI systems are likely to use both: MCP to give their agents powerful abilities, and A2A to allow multiple agents (or AI services) to cooperate.
- Real-world Case Studies: We are still early, but we can envision case studies soon. For example, a car repair shop AI system described by Google: the shop has robotic tools that can be controlled via MCP (e.g., an MCP server to move a lift or operate a wrench), and it has agents representing mechanics that communicate via A2A with customers and supplier agents. In this scenario, MCP handles the physical tool commands (“raise platform”, “turn wrench”) while A2A handles the interactive dialogue and coordination (“send me a photo of the part”, “order a replacement from supplier agent”). This illustrates vividly how in a single workflow both protocols interweave.
Looking ahead, the success of these protocols will depend on ecosystem growth. If many tool providers publish MCP servers (the way many services publish APIs today), and many agent providers publish A2A-compatible agents, we could see an “API economy” equivalent for AI agents. Businesses benefit by not having to reinvent connectors or integrations for each AI project – they can leverage standard components. For AI developers and architects, learning MCP and A2A will likely become important, akin to knowing how to call REST APIs.
MCP vs A2A: Summary Comparison
Finally, here is a quick summary comparison of MCP and A2A across key dimensions:
| Aspect | MCP (Model Context Protocol) | A2A (Agent-to-Agent Protocol) |
|---|---|---|
| Primary Purpose | Connect AI agents to external tools, data, and context at runtime. (MCP) | Enable communication between AI agents across orgs. [GitHub] [Koyeb] |
| Architecture | Client–Server model: MCP Client connects to tool-specific MCP Servers. [Docs] | Peer model over HTTP: Agents act as Clients & Servers using Agent Cards for discovery. |
| Communication | JSON-RPC 2.0 via stdio/HTTP+SSE. Tool calls are one-off or chained. Notifications supported. | JSON-RPC 2.0 over HTTP. tasks/send with streaming and async notifications. Multi-turn dialogue enabled. [Koyeb] |
| Capabilities Exposed | Tools, Resources, Prompts. Defined by server. Used by agent at runtime. | Skills listed in Agent Card (e.g., Translate, Analyze). Modalities (text, files, audio) negotiated live. |
| Agent Memory & Context | Injects relevant data via resources. Session memory can use vector DBs, etc. [Examples] | Memory is local to each agent. Context is passed through task messages only. No shared state. |
| Integration Targets | LLM apps (assistants, chatbots, IDEs). SDKs for OpenAI, Anthropic, open models. Tool plugins for Slack, Stripe, etc. | Multi-agent enterprise ecosystems. CRM, ERP, support bots collaborating. Works in LangChain, Semantic Kernel, etc. |
| Performance | Lightweight. Local or quick calls. Supports streaming for large results. Real-time friendly. | Some HTTP overhead. Supports both real-time and long tasks. Allows parallelism across agents. |
| Reliability & Scaling | Failure of one tool doesn’t break session. Scales by adding MCP Servers. Typically single-user agents. | Scales across distributed agents. Task IDs enable reconnection. Load-balancing supported. Secure API-like model. |
| Example Workflows | Single-agent: Customer bot uses MCP to fetch purchase history, submit ticket, and respond live. | Multi-agent: Sales, Inventory, and Finance agents coordinate on a quote – each with their own domain skill. |
As shown, MCP and A2A shine in different but complementary areas. MCP equips an AI agent with the tools and knowledge to act within its environment, making it highly capable in a specific context (business data, APIs, etc.). A2A enables multiple such agents (each potentially MCP-equipped) to form a collaborative team, tackling complex, cross-domain business workflows. Rather than choosing one or the other, organizations can combine MCP and A2A to build powerful agent ecosystems – using MCP for deep integration with their systems and A2A for broad integration across agents and services. Together, these protocols represent a significant step toward scalable, maintainable agent-based business process automation, supported by open standards and a growing community of adopter.
Until the next one,
Tega AdeyemiApril 30, 2025