Articles & Playbooks
Your AI Guardrails Aren’t Broken. They’re Just Missing Half the Brain.
Dense embeddings understand meaning. Sparse matching catches specifics. Hybrid routing gives you both—fast.
Guardrails for Agents: One Layer Is Never Enough
When we’re building anything conversational—agents, chat apps, “helpful widgets that definitely won’t become chaos portals”—guardrails aren’t a single wall.
They’re a stack:
- Input guardrails / routing: Can this request enter the system? Where should it go?
- Prompt-level guardrails: How we instruct the LLM to behave safely.
- Output guardrails: Did the LLM generate something we should not ship?
A typical flow looks like:
- User message → Initial guardrails
- If blocked: send a pre-written response, or route to a “safety handler” model
- If allowed: continue
- Allowed message → LLM (with safety prompting)
- LLM response → Output checks
- Clean response → User
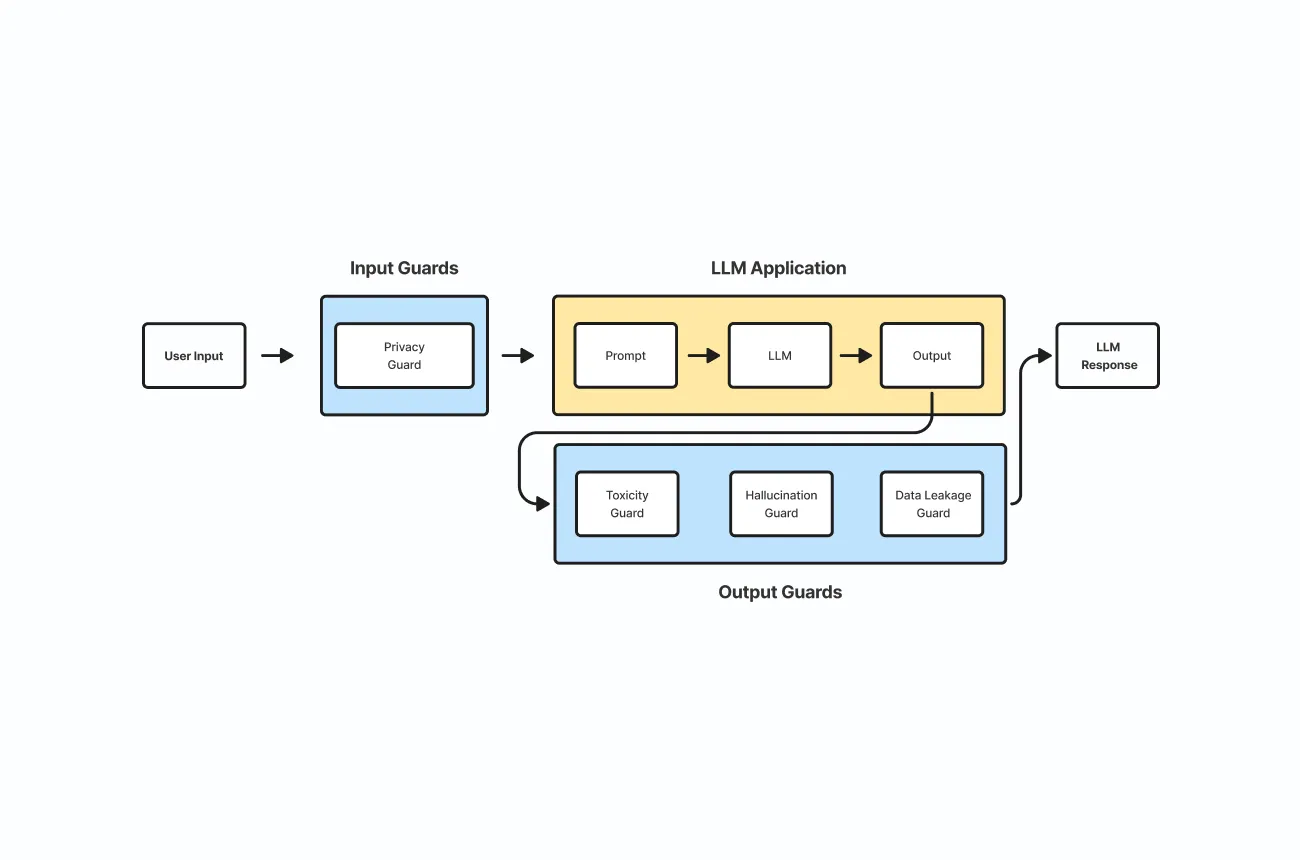
Key takeaway: The best guardrail is the one that prevents risky prompts from ever reaching the model.
The Routing Layer: The Quiet MVP
Routing is where we decide scope:
- ✅ “We can talk about this” (allowed zone)
- 🚫 “We don’t touch this” (blocked zone)
- ⚠️ “We can talk about this only in a very specific way” (overlap edge cases)
For builders, routing is the difference between:
- an agent that’s reliably helpful
- and an agent that’s “helpful in a way that gets us on a call with Legal”
Why Semantic Routing Alone Can Betray You
Semantic routers use dense embeddings.
We embed a query into a vector space so that similar meanings land near each other.
Example queries:
- “Can I sell my Tesla?”
- “Can I sell my Polestar?”
- “Can I sell my BYD?”
- “Can I sell my Rivian?”
Semantically, these are basically siblings. Same intent, similar language.
So the similarity scores can be surprisingly high across brands.
That’s great for understanding meaning.
It’s terrible when the product requirement is:
“We only discuss BYD. Competitors are out of scope.”
Because the embedding model doesn’t care about your brand boundaries. It cares about language meaning.
Key takeaway: Dense embeddings are brand-blind. They’ll happily treat competitors like cousins.
Sparse Matching: The “Actually Read the Words” Approach
Before dense embeddings became the default, we relied on things like BM25 / TF-IDF.
These use term overlap:
- “Tesla” matches “Tesla”
- “BYD” matches “BYD”
No philosophical debates. No “semantic proximity.” Just: did they say the thing?
That creates sparse embeddings—excellent for:
- brand names
- model numbers
- product SKUs
- regulated phrases
- competitor detection
Key takeaway: Sparse signals are blunt—exactly what we want for strict scope control.
Hybrid Guardrails: Dense + Sparse = Fewer Facepalms
Hybrid routing merges:
- Dense similarity (semantic meaning)
- Sparse similarity (term matching)
So we get:
- semantics for “what are they trying to do?”
- term matching for “who are they talking about?”
Example: the competitor trap
User: “Can I buy a Tesla from you?”
- Dense: “purchase intent, EV-related”
- Sparse: “TESLA detected”
- Hybrid: Route to Tesla policy (block / deflect / competitor-safe response)
That’s the entire win in one line:
Hybrid understands the intent and respects the boundaries.
.webp)
Key takeaway: Hybrid routing is how we stay smart without being naive.
The Setup: Routes and Utterances (Yes, They Matter)
To make this work we define routes—think categories with example utterances.
Example routes:
- BYD (allowed)
- Tesla (blocked/handled)
- Polestar (blocked/handled)
- Rivian (blocked/handled)
The utterances aren’t decoration. They shape the space:
- Dense space learns what “BYD questions” mean
- Sparse space learns what “BYD questions” contain
Key takeaway: Your utterances are training wheels for routing. Better examples = better guardrails.
The Part Everyone Skips: Thresholds (And Then Wonders Why Everything Breaks)
Hybrid scoring is a merger of two systems, so thresholds become less intuitive.
If thresholds are too low, we get the classic disaster:
User: “How do I start a vegetable garden?”
Router: “This feels… Tesla-ish.” (It is not.)
Not because the router is “bad,” but because the threshold is so permissive that random text trips routes.
Key takeaway: Default thresholds can be fine for demos—and brutally wrong for real traffic.
The Fix: Fit Thresholds Using Test Data
We don’t guess thresholds. We fit them.
We create a test dataset:
- Utterance → expected route label
- Include plenty of “None” examples (pass-through queries)
Examples for None:
- “What’s the best way to cook a steak?”
- “Who was the first person to walk on the moon?”
- “How much is a flight to Australia from Europe?”
Then we run evaluation:
- With default thresholds, accuracy can land around ~51% on a more realistic set.
- After fitting thresholds, accuracy can jump to ~95–96%.
And the router finds route-specific thresholds like:
- Tesla: ~0.57
- Polestar: ~0.34
- Rivian: ~0.71
Different routes need different sensitivity. Hybrid makes that normal.
Key takeaway: Fitting thresholds turns hybrid routing from “cool idea” into “production tool.”
Quick Real-World Checks (The Only Tests We Actually Trust)
After fitting:
- “Can I buy a Tesla from you?” → Tesla route
- “How much is a flight to Australia from Europe?” → None
Now the router blocks what we need, and lets harmless queries pass.
That’s what “good guardrails” feel like: boring reliability.
Key takeaway: Great guardrails don’t feel strict. They feel invisible.
Putting Hybrid Routing in Context: It’s One Layer—A Critical One
Hybrid routing shines as the input guardrails layer:
- insanely fast
- cost-effective
- strong accuracy after fitting
- better brand scope control than semantic-only routing
But we still want the full stack:
- prompt constraints
- output filtering
- optional rules-based checks (hard constraints, banned terms, formats)
- additional classifiers when needed
Key takeaway: Hybrid routing is the gate. Not the entire castle.
The Builder’s Checklist
If we’re shipping this for real, we do:
- Define routes (allowed + blocked + special handling)
- Populate utterances (realistic, messy, typo-friendly)
- Build a test set with lots of “None”
- Evaluate defaults
- Fit thresholds
- Expand test coverage continuously
- Keep input + output guardrails in production, always
And yes—using an LLM to generate extra test utterances can help quickly scale coverage. Just don’t treat it as gospel. Treat it like a junior intern who’s brilliant and occasionally confident about nonsense.
When we combine dense understanding with sparse precision, guardrails stop being a fragile patch—and start becoming a system we can trust.
And then, when the user asks about selling a Tesla?
We don’t panic.
We route.
— Cohorte Intelligence
February 6, 2026