Articles & Playbooks
The open-source stack finally clicked—here’s the builder playbook: what it is, when to use it, and two local agents you can run today.
What Open Source AI Actually Means and What It Doesn’t
Open source AI refers to AI systems where some or all core components are publicly available, usually including:
- model architecture
- model weights
- training and/or inference code
- a license that allows use, modification, redistribution
Closed-source AI keeps weights and training proprietary. You access it through:
- APIs
- web apps
- enterprise platforms
Closed-source examples: GPT (OpenAI), Claude (Anthropic), Gemini (Google), Grok (X).
Key takeaway: Open source is not “free chat.” It’s control over the engine.
The Builder Decision Rule: When Open Source Wins and When It Doesn’t
Let’s make this practical.
Use open source when:
You have sensitive data (finance, email, contracts, health)
You need predictable cost (high volume, always-on agents)
You want customization (fine-tuning, guardrails, local tools)
You need auditability or strict compliance
You want no vendor lock-in
Use closed source when:
You need best-in-class capability today with zero setup
You’re prototyping fast and data is non-sensitive
You need managed reliability (ops, scaling, uptime handled)
Key takeaway: Open source is a deployment strategy as much as a model choice.
“So we should switch everything to open source?”
“No.”
“So we should ignore it?”
“Also no.”
“So what do we do?”
“We use open source where privacy + cost + control matter most.”
The Moment Open Source Became “Real”
Since 2022, closed-source dominated because it was simply better.
Then January 2025 hit and DeepSeek R1 proved a point the whole industry felt:
Open models could compete near the top — and that opened the floodgates.
Now in February 2026, the list of strong open models keeps rotating. The names will change. The pattern won’t.
Key takeaway: The “open source is always behind” assumption is no longer safe.
“Are the Best Open Models Chinese?” Often, Yes. Here’s Why That’s Not Your Server Problem.
A lot of leading open models have come from Chinese labs, and usage patterns have reflected that shift.
This triggers the classic worry:
“Does that mean our data is going to Chinese servers?”
No.
Open source means you can run the model locally.
On your laptop. In your VPC. In your private cloud. In an air-gapped environment.
Model origin ≠ where inference runs.
Key takeaway: With open source, you choose where compute happens.
The Tradeoffs
Open source has real costs:
- setup complexity (more wiring than “click and chat”)
- hardware constraints (models are heavy)
- fewer built-in bells/whistles out of the box
- you own ops (security, uptime, scaling)
But these are shrinking fast thanks to:
- quantization (smaller models)
- better inference runtimes
- smoother tooling and starter kits
Hardware sizing cheat sheet (simple version)
- Small models (7B-ish): great on many laptops, good for workflows + drafts
- Medium (13B–32B-ish): stronger reasoning, needs more RAM/VRAM
- Large (70B-ish+): impressive, usually needs serious GPU setup

Key takeaway: Open source is becoming “builder-accessible,” not “research-only.”
The Open Source AI Stack (What You Actually Need)
When we say “stack,” we mean: the pieces you need to go from model → agent.
1) Models
As of Feb 2026, examples to watch:
- Kimi (Moonshot AI)
- GLM (Zhipu → now Z.AI)
- Hunyuan (Tencent), especially for image tasks
Rankings change constantly, but the workflow stays consistent.
2) A model manager (run models locally)
You’ll typically use a model manager like Ollama:
- install
- pull a model
- run it locally
That’s the “model” component handled.
3) Agent/workflow layer
Agents still use the same core components:
- models
- tools
- knowledge
- memory
- guardrails
- orchestration
Open-source agents aren’t different — they just run on open models.
Key takeaway: If you’ve built agents before, this is not a new religion. It’s the same architecture with different plumbing.
Your 15-Minute Activation Path (Do This Before Reading Another Thread)
If you only do one thing from this post, do this:
- Install a model manager (e.g., Ollama)
- Download one model that fits your machine
- Run one local prompt
- Confirm: no data leaves your device
That’s it. That’s the “open-source click” moment.
Key takeaway: Don’t overthink. Get to “first local prompt” fast.
No-Code Demo: Private Financial Document Analyzer (n8n + Ollama)
Here’s where open source stops being theory and starts being useful.
We build an agentic workflow that:
- reads credit card statements stored locally
- extracts data
- sends it to a local open-source model (e.g., Qwen 38B)
- outputs categories, insights, cost-saving suggestions
- keeps everything on-device
Example output:
- monthly category breakdown (July/August)
- biggest spend: digital services + travel
- suggestions: cancel unused subscriptions (Heroku, Medium, Slack), downgrade plans
- estimated annual savings + action items
How builders would extend it
- add bank statements + investments for full picture
- schedule it weekly
- create a dashboard view
- pull documents automatically from sources you control
Key takeaway: Open source makes “sensitive doc automation” finally feel safe.
Code Demo: Local Email Agent (Python + Ollama + Agents SDK)
Now the builder build.
This agent:
- fetches unread emails (e.g., last 5)
- classifies which need replies
- drafts replies
- ignores promotions
- flags suspicious messages for human review
Example behavior:
- interview invite → drafts availability reply
- promotions → ignored
- automated job listing with weird HTML/short links → flagged for human
And importantly: it drafts, but doesn’t auto-send until we approve.
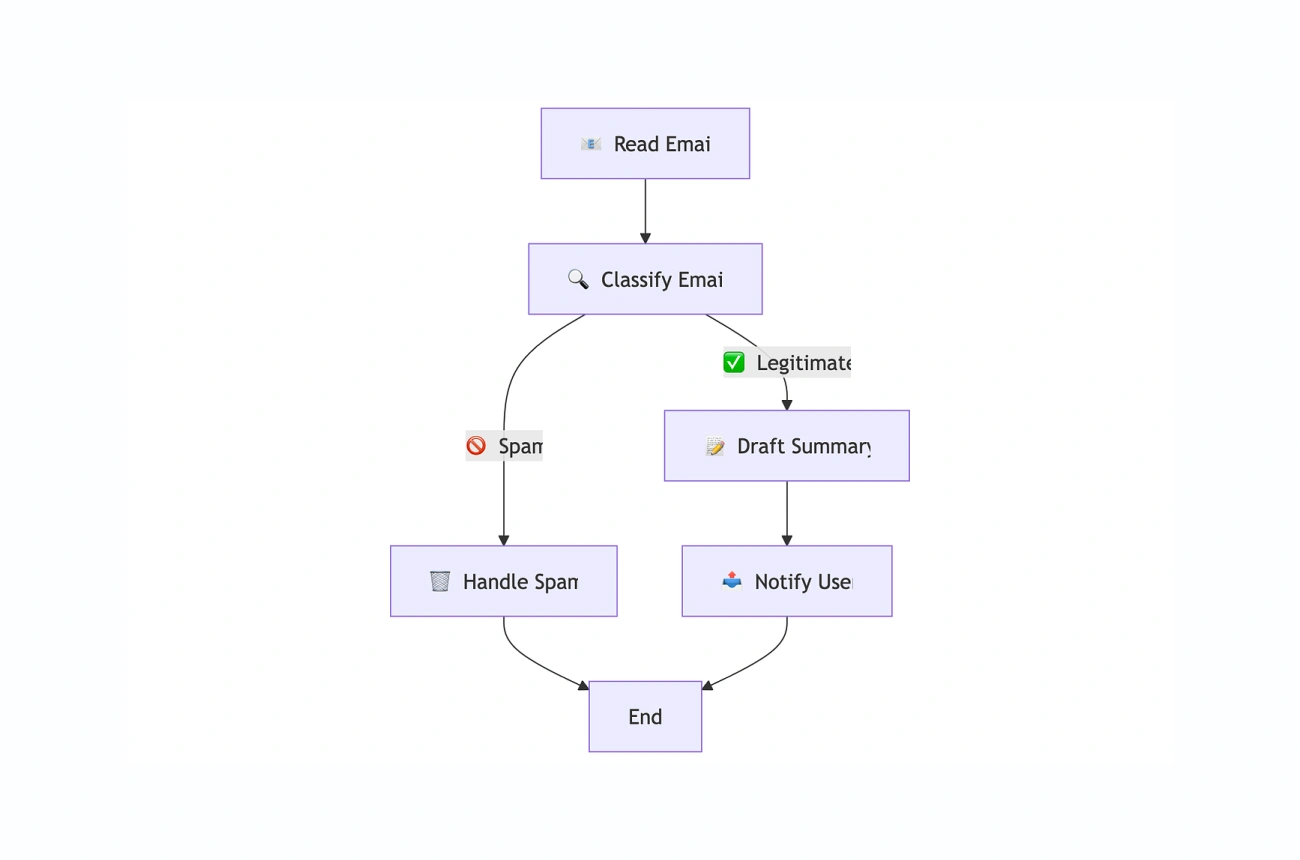
Key takeaway: Local agents are how we scale communication without sacrificing privacy.
Quiz Time
Quiz 1
- Name two “core components” that commonly make an AI system open source.
- One major advantage + one drawback of open-source AI?
- Why doesn’t model origin determine where data runs?
Quiz 2
- List the key components of an AI agent.
- What does a model manager do?
- Why are finance + email perfect first use cases for local agents?
- What’s one upgrade you’d make to either demo?
The Bottom Line: Open Source AI Makes AI Feel… Deployable
Most AI hesitation is rational:
- “What happens to our data?”
- “How much will this cost if we run it daily?”
- “Are we locked in?”
- “Can we audit and control it?”
Open source doesn’t solve everything.
But it meaningfully shifts the tradeoffs toward:
- privacy by default
- predictable cost
- customization
- ownership
And in 2026, it’s finally accessible enough that builders can adopt it without a GPU farm and a prayer.
Key takeaway: Open source isn’t replacing closed source. It’s unlocking workflows closed source makes uncomfortable.
— Cohorte Intelligence
February 13, 2026