
Why new models?
Have you ever asked this question?
You’ve been using your favorite AI for a while and then… AI providers just decide to flood the market with “new ones”.
I’ve been trying to write this letter for weeks now.
Every time I sat down to analyze the latest “genius” AI model, three more would drop before I could finish typing.
Just look at the past couple of weeks:
Monday: Claude-3.7 rewrites the game.
A few days later: Gemini 2.5 Pro is the new standard.
A few days later: OpenAI’s o3 and o4 are going to smash everyone else. (They didn’t.)
A few days later: Actually, the new standard is GPT-4.1. Not 4.5.
...
Each announcement bigger than the last. Each claim more outrageous than before. The tech news cycle turned into an endless stream of "forget everything you knew about AI" headlines.
So I waited.
Finally, a ceasefire. Maybe.
A rare week without a new launch.
Just long enough to write this before it gets outdated (maybe by the time you read this).
Let’s talk about what’s really happening.
⚡ The AI Arms Race Just Leveled Up
A couple of weeks ago, OpenAI released two new reasoning models — gpt-o4-mini and gpt-o3 (for paid subscriptions).
To be very precise, these are not exactly LLMs (or models); for me, these new creations are more like agents (they auto-reflect and search the web, etc.) than just "a model" per se.
People are already calling them “genius-level.”
(which isn't completely absurd, by the way)
But if that’s 100% true, we should be riding superconducting hoverboards by next week.
I would call them "powerful" or "potent," not really "genius"...
Because every few weeks, someone drops a "Genius Model" — impressive for solving many search, information retrieval, and "moderate problems," and great for being your "therapist," but usually failing badly at solving more complex, multi-task problems or doing complete end-to-end tasks with an "acceptable" level of "trust."
Still… OpenAI and other AI providers are shipping like mad.
Let’s zoom out for a second:
OpenAI
| Date | Release |
|---|---|
| February 27, 2025 | GPT-4.5 research preview [OpenAI] |
| April 14, 2025 | GPT-4.1 series API-only models [OpenAI] [OpenAI] |
| April 16, 2025 | OpenAI o3 & o4-mini with full tool access [OpenAI] [OpenAI] |
| April 16, 2025 | OpenAI Codex CLI (command-line coding agent) [OpenAI] |
Anthropic
| Date | Release |
|---|---|
| February 24, 2025 | Claude 3.7 Sonnet hybrid reasoning model & Claude Code CLI preview [Anthropic] |
| May 1, 2025 | “Claude can now connect to your world” Integrations beta [Anthropic] |
| May 5, 2025 | Introducing Anthropic’s “AI for Science” program [Anthropic] |
| May 7, 2025 | Web search on the Anthropic API (feature preview) [Anthropic] |
| Date | Release |
|---|---|
| March 25, 2025 | Introducing Gemini 2.5 (Pro Experimental) thinking model [blog.google] |
| April 4, 2025 | Start building with Gemini 2.5 Pro (public preview in AI Studio) [blog.google] |
| April 8, 2025 | Deep Research capability on Gemini 2.5 Pro Experimental [blog.google] |
| April 17, 2025 | Gemini 2.5 Flash preview (fast, cost-efficient thinking model) [blog.google] |
Confused by the naming? You’re not alone.
We’re talking about o4, not 4o.
Keep up. It’s a full-time job now.
🪓 Tools Everywhere, Focus Nowhere
Let’s take coding — one of the top AI use cases.
The dev tool space is insane right now.
| Tool | What’s special? |
|---|---|
| Codeex | Terminal-first. Powered by OpenAI models. |
| Claude Code | Can reason deeply, slower output. |
| Cursor | VS Code fork with slick in-editor AI UX. |
| Windsurf | Another VS Code fork. Possibly getting acquired by OpenAI for $3B. |
| Firebase Studio | Browser-based IDE by Google. Auto-deploy. Uses Gemini 2.5. |
| GitHub Copilot (Agent Mode) | Microsoft’s power play: file creation, command execution, context integration. |
This list is not exhaustive: many people are also using CLINE, which is a nice free VS Code extension…
And here’s the twist: most of these tools are just slightly altered versions of VS Code.
It’s wild.
Cursor is doing $100M ARR. Windsurf might sell for billions.
Meanwhile, some people and companies wasted three years building AI-powered tools when they should’ve just forked VS Code and added AI.
Let's also not forget that the "AI revolution" is also a massive graveyard of 2020-2022 startups that were massively funded in the "easy money" era…
🏆 Are o3 and o4 Really Game Changers?
For those who are familiar with this letter know that one of my favourite exercices is model comparison.
I’m not running extensive studies like “research papers” benchmarks and more general and comprehensive metrics. We’re just trying to get a qualitative glimpse of what new “models” offer for “regular” tasks to get a sense of what one can really expect and what to use for what?
If you’re interested in previous studies and comparisons, you can check out those previous letters:
- Reasoning models comparison (o1, Grok3, DeepSeek)
- Deep Search Tools comparison
- Image generation and editing comparison
Before we start a quick reminder. All the models compared here fall in the category of “reasoning models” — not regular LLM models like GPT-4o.
A quick reminder: what’s the deal with reasoning models?
Think of AI in two flavors:
- Non-reasoning models → Fast thinkers, great for creative tasks and spitting out quick answers. (Think GPT-4o, the regular free ChatGPT.)
- Reasoning models → The deep thinkers. They take time to “think aloud,” generating a chain of thoughts, reflecting on each step, and self-correcting if necessary. (Examples: OpenAI’s o1, o3, and o4 models.)
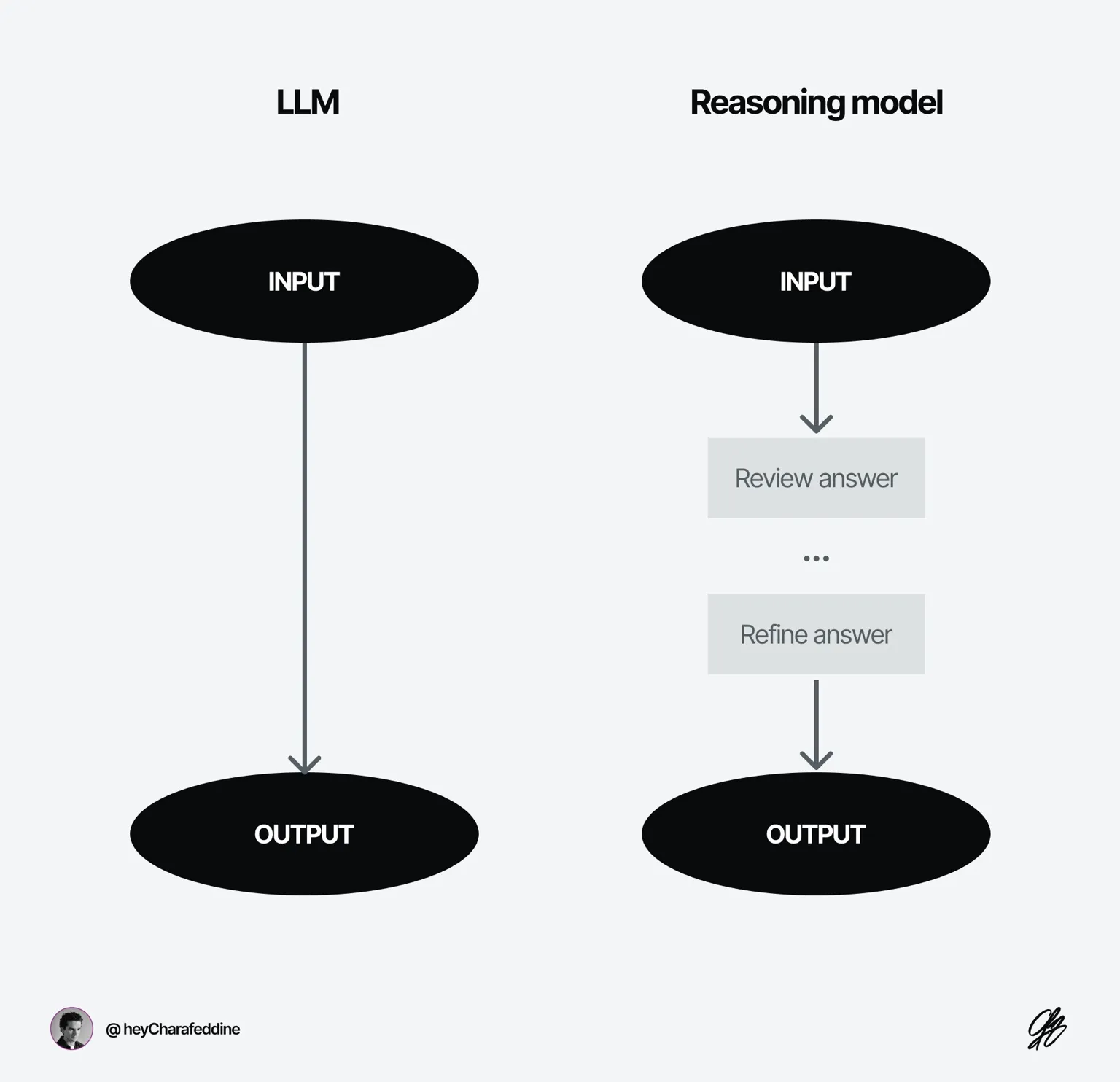
How an LLM responds (left) and how a reasoning model does (right).
The definition of 'reasoning' varies between AI labs, but most agree it means the model takes extra time to review and refine its answers before responding.
🔬 The Tests
The models:
- 4o (the free ChatGPT model)
- o1 (based on my tests during the past letters)
- o3
- o4-mini
- Claude 3.7 (with reasoning)
- Gemini 2.5 Pro
Here's what I'm going to do: I'll take these AI models for a spin, putting them through their paces on 4 real-world challenges.
As I said, nothing too academic or fancy - just practical, everyday stuff you might actually use. By the end of this letter, I'll give you my honest take on whether these "new genius models" are worth the hype.
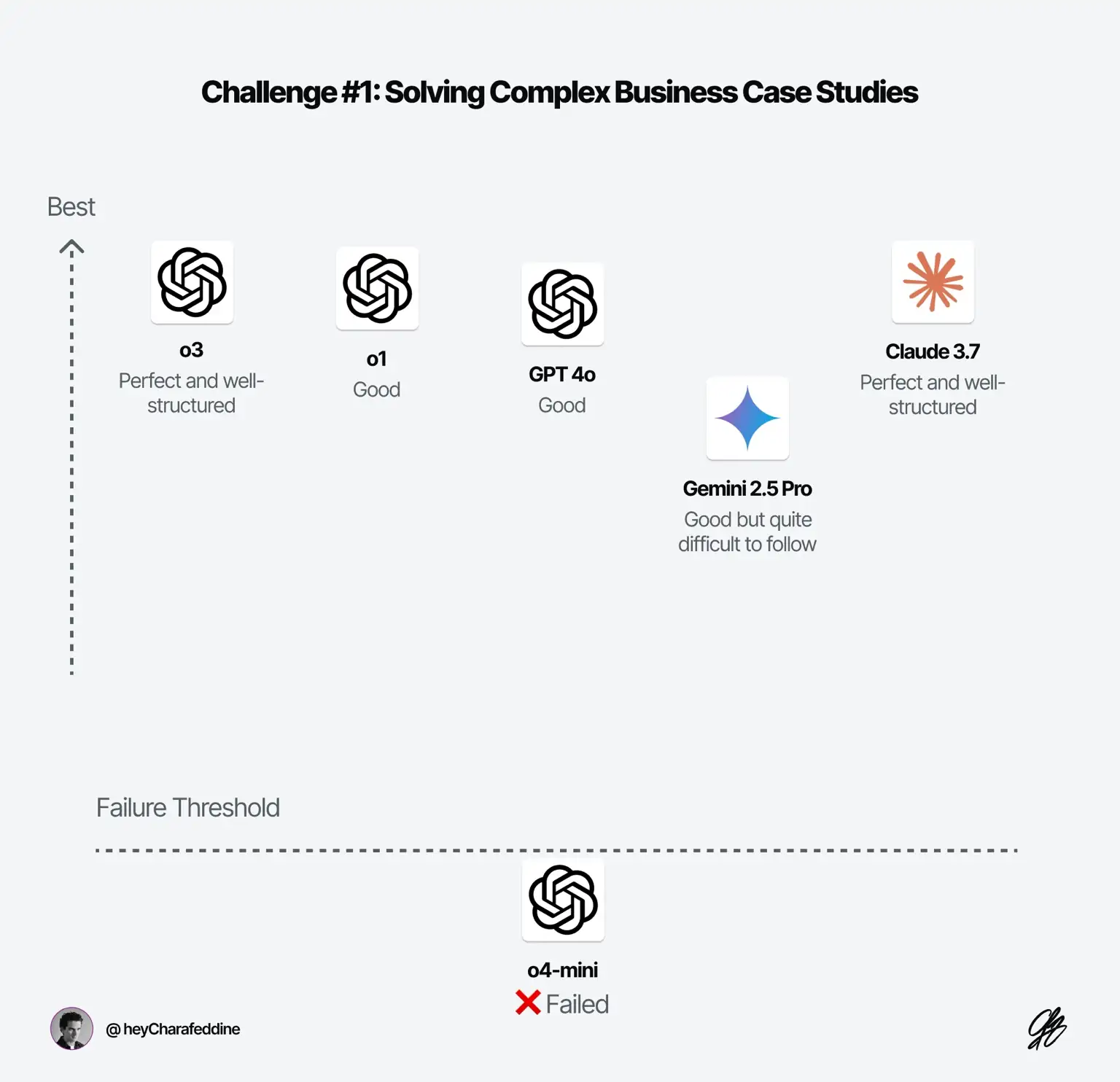
Challenge #1: Solving Complex Business Case Studies
Problem #1:"You're working for a bank to enhance performance of a corporate credit options product. The bank only makes money when a contract is activated. Total signed contracts consist of active contracts (which generate profit) and inactive contracts. Given that you have access to both the average revenue per activated contract and the average cost per contract, what is the formula for profit per signed contract? Assuming the average revenue per activated contract is $2,500 and we increased the number of activated contracts by 25% while the total numbed of signed contracts remained the same, what would be the increase in profit per contract?”
I used to pose this exact case study to junior strategy consultants during interviews. Over two years, I tested more than 150 candidates between 2019 and 2021 from the world's top universities — we're talking brilliant minds here. Want to know something interesting? Even with 20–40 minutes and the ability to ask questions, only about 25% could crack it with a solid explanation. Now let's see how our "AI friends" handle it...
Everything you see below represents average measures across 30 runs.
The Results:
- ❌ o4-mini (8s): Wrong reasoning (most of the time) at the final steps.
- ✅ o1 (45s): Great explanation—short, sharp, and easy to follow.
- ✅ Claude 3.7 + No Reasoning: Good.
- ✅ Gemini 2.5 Pro + Reasoning (1s): Good. The output is neither very clean nor well structured in comparison to other "reasoning models".
- ✅ o3 (57s): Perfect. Better structure and explanation than all models. Uses tables to structure information more frequently than o1.
- ✅ GPT-4o (0s): Good.
Solution example:
Example of a perfect and concise answer by o3
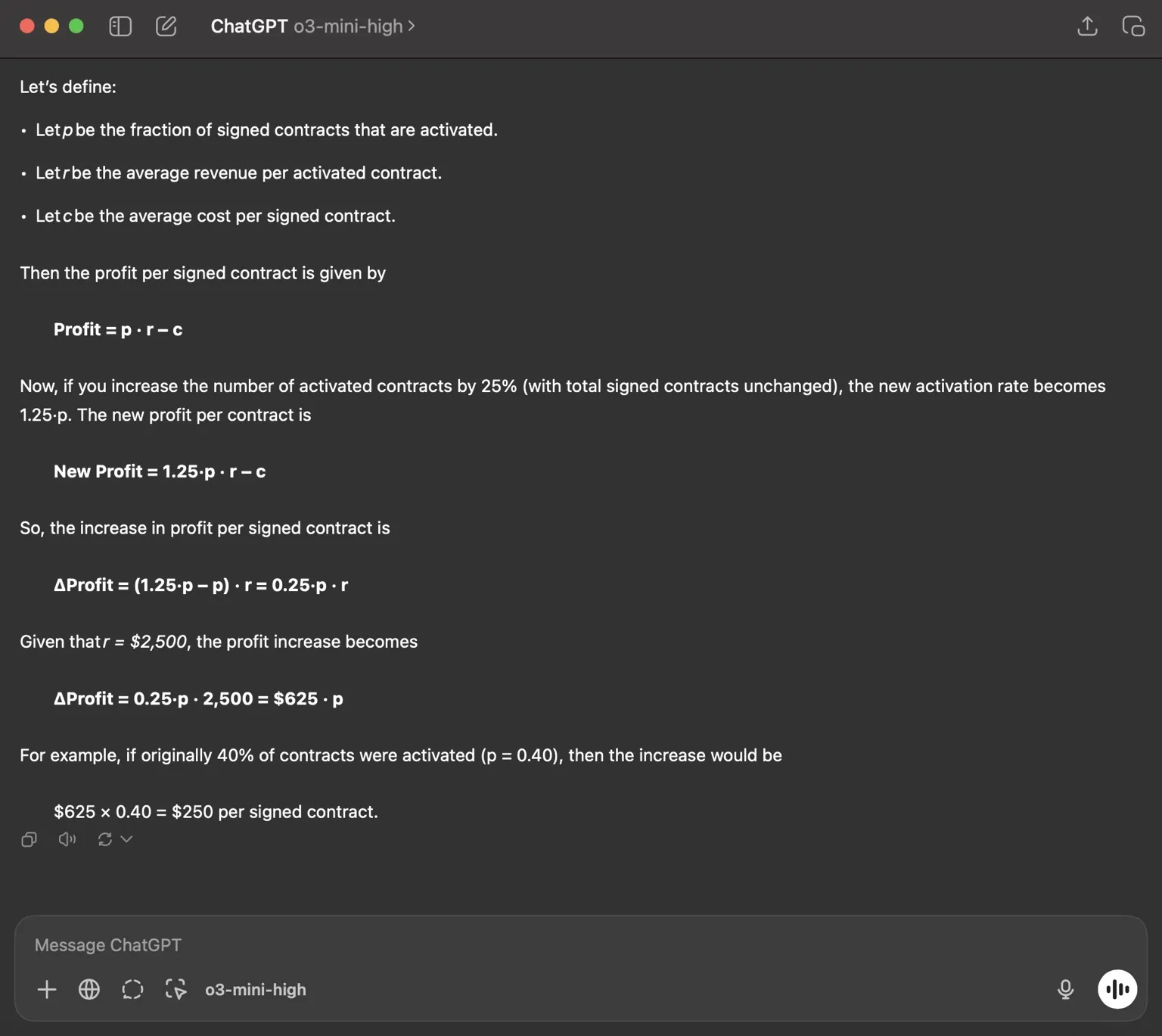
Takeaway: While the task seems reasoning-based, the "non-reasoning" models like 4o and Claude 3.7 solved the problem without difficulty. I'm surprised by o4-mini's inability to solve this problem consistently most of the time. The “new genius models” doesn’t seem to add anything in this context.
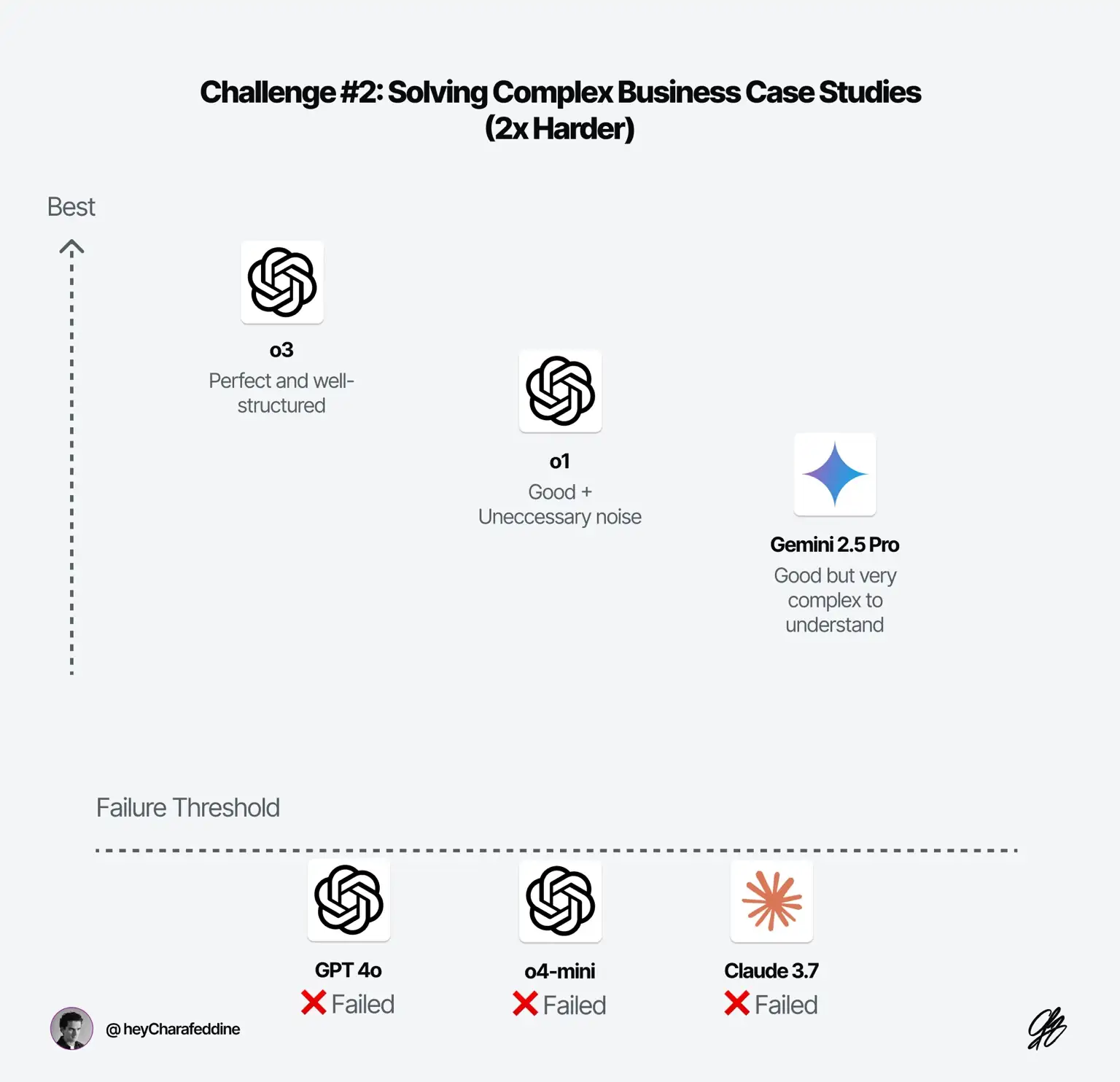
Challenge #2: Solving Complex Business Case Studies (Harder)
Let's push this test further by adding an optimization challenge with uncertainty.We'll ask each AI to help us allocate our efforts more efficiently depending on different probable scenarios.
Problem#2: “You're working for a bank to enhance performance of a corporate credit options product. The bank only makes money when a contract is activated. Total signed contracts consist of active contracts (which generate profit) and inactive contracts. Given that you have access to both the average revenue per activated contract and the average cost per contract, what is the formula for profit per signed contract? Assume we have 4 contract categories.The average revenue per activated contract is $2,500, $1,000, $200, and $200 respectively. One unit of effort can enhance the number of activated contracts by 5%, 10%, 2%, and 40% respectively across the categories, while the total number of signed contracts remains the same. We have only 4 units of effort to spend with a 40% probability and only 3 units with 60% probability. We can’t use all the unit on one category. What's the best allocation of effort across categories to maximize the profit per contract?”
Everything you see below represents average measures across 30 runs.
The Results:
- ❌ o4-mini (16s): Wrong result and reasoning (most of the time).
- ✅ o1 (45s): Good explanation. Added unnecessary complexity in several steps.
- ❌ Claude 3.7 + No Reasoning (0s): Almost there, but wrong most of the time.
- ✅ Gemini 2.5 Pro + Reasoning (1m 30s): Good but very complex to understand most of the time (for people with no or little math background).
- ✅ o3 (1m 23s): Perfect.
- ❌ GPT-4o (0s): Almost there, but wrong most of the time.
Solution example:
Example of a perfect and concise answer by o3
Takeaway: Now we have a task that appears to be accessible only to “good” reasoning models (o4-mini failed badly though). o3 seems to be the best in its category for both reasoning and quality. While Gemini 2.5 Pro solves the problem with high accuracy, its presentation of results is very complex (see the image below).
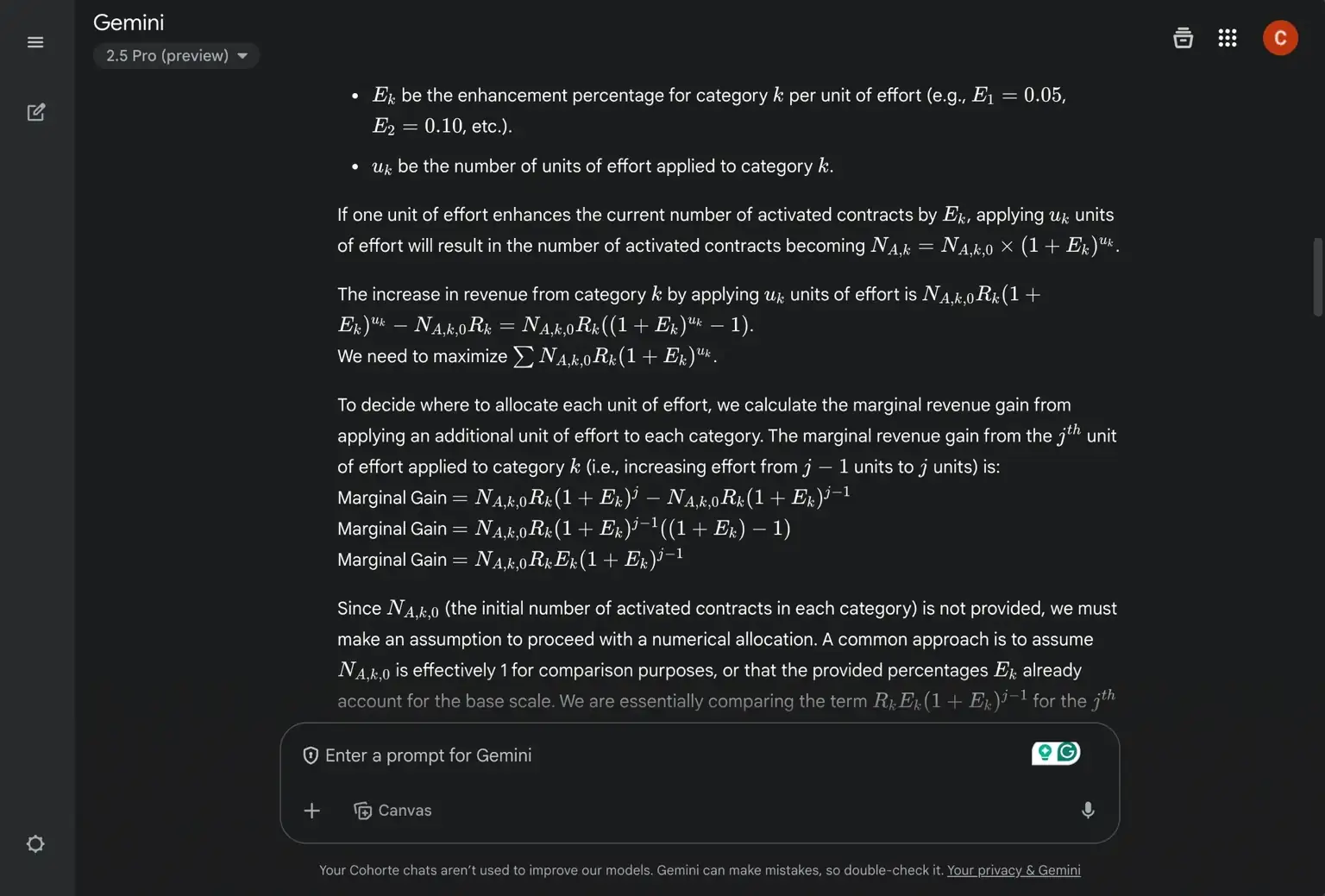
While this example shows clearly the importance/value of “reasoning” models, though I couldn’t see an additional value of “new genius models”, like o3, in comparison to “old advanced models” like o1 (removed my OpenAI from ChatGPT—as an “old model”).
Let's try a PhD-level problem—something OpenAI frequently touts their new models can handle...
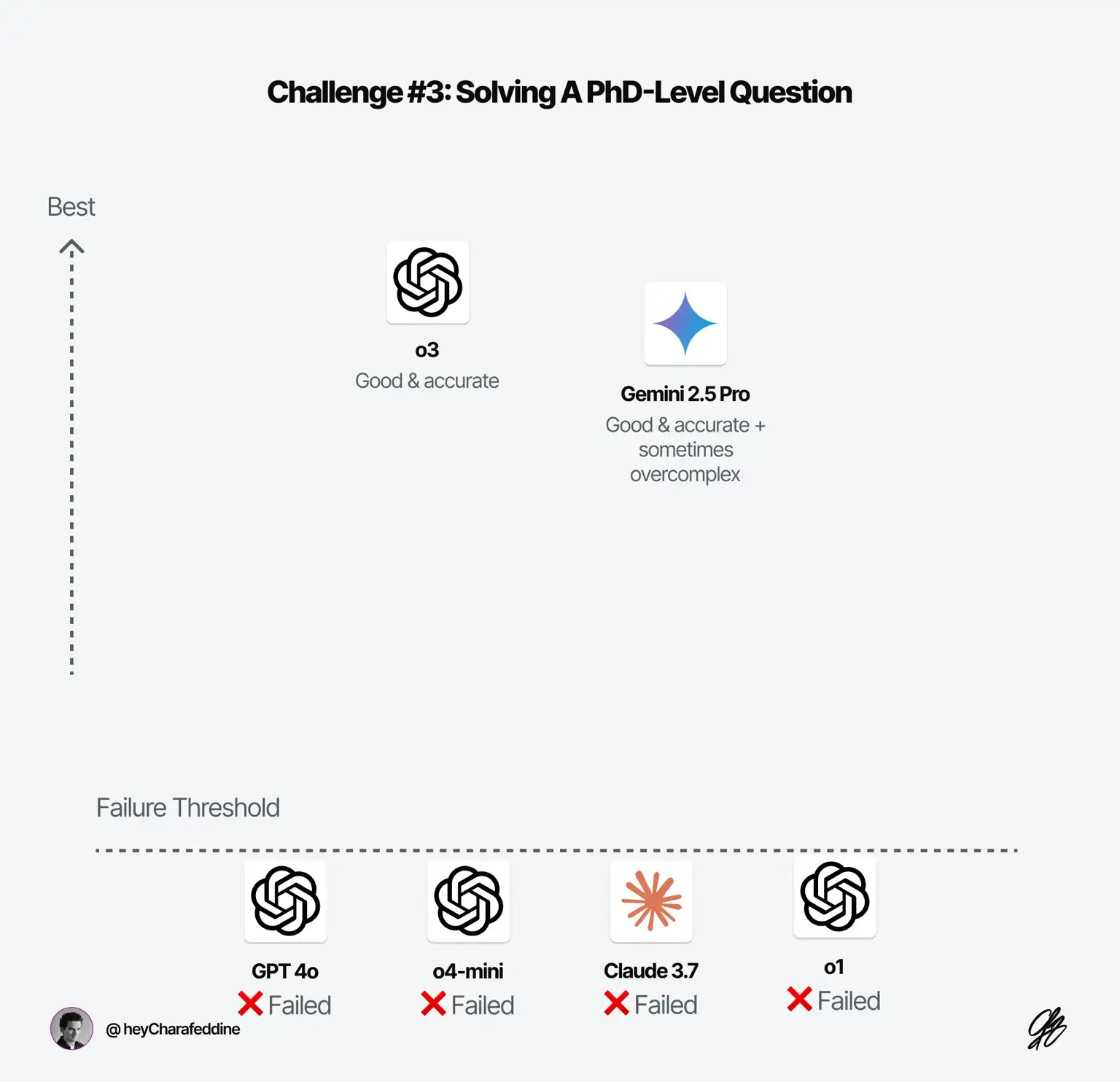
Challenge #3: Solving A PhD-Level Question
Please note that the question I'm going to ask is very niche and would make little sense to most of you. However, I know that such a question can only be answered by a "good math PhD student" — I was a PhD student working on the similar problems years ago.
You can try this yourself with a "very niche high expertise question" from your own domain of expertise.
Let’s go.
Problem#3: “Solve the following math problem.
Define a collection of correlated Brownian motions, \{X^{i,N}\}_{i=1,\ldots,N}, started on the half-line and evolving with a standard dynamics:
X_t^{i,N} = X_0^i + \int_0^t \rho(L_s^N)\,dW_s + \int_0^t \sqrt{1 - \rho(L_s^N)^2}\,dW_s^i,
where the empirical loss process is defined as:
L_t^N := \frac{1}{N} \sum_{i=1}^N \mathbf{1}_{\{\tau^{i,N} \leq t\}},\quad \text{with} \quad\tau^{i,N} := \inf\{t > 0 : X_t^{i,N} \leq 0\}.
Here, W, W^1, W^2, \ldots are independent Brownian motions, and \{X^i\}_{i \geq 1} are i.i.d. with some density f : (0, \infty) \to [0, \infty). The function \rho : [0, 1] \to [0, 1] is measurable. No further regularity is imposed on \rho in the tightness calculations that follow. This system describes how the proportion of particles that have hit the origin influences the correlation in the system.
To see that such a collection \{X^{i,N}\}_{i=1,\ldots,N} exists, note that t \mapsto L_t^N is piecewise constant. Therefore, to construct the discrete system, take N Brownian motions with initial correlation \rho(0), stop the system at the first hitting of zero, restart with correlation \rho(1/N), and repeat this process.
Our setup generalizes the constant correlation model introduced in [8]. The motivation for this formulation is to address the correlation skew observed in [8, Sec. 5]. To analyze the model, we consider the empirical measure of the population:
\nu_t^N = \frac{1}{N} \sum_{i=1}^N \mathbf{1}{\{t < \tau^{i,N}\}} \delta{X_t^{i,N}},
so that:
L_t^N = 1 - \nu_t^N((0, \infty)).
Here, \delta_x denotes the Dirac delta measure at point x \in \mathbb{R}.
Your task is to establish the weak convergence (at the process level) of (\nu^N)_{N \geq 1} to some limit \nu, which should satisfy the non-linear evolution equation:
d\nu_t(\phi) = \frac{1}{2} \nu_t(\phi’’)\,dt + \rho(L_t)\nu_t(\phi’)\,dW_t, \quad L_t = 1 - \nu_t((0, \infty)),
for test functions \phi \in \mathcal{S} satisfying \phi(0) = 0.”
Sorry for this graffiti. If you don't understand what it means, don't worry—just know that this is a PhD-level math problem.
Now, let's see how these "Genius AI models" handle it.
Everything you see below represents average measures across 30 runs.
The Results:
- ❌ o4-mini (26s): Wrong results and reasoning (most of the time).
- ❌ o1 (1m): Failed on a couple of results. The model seems to have a lack of knowledge and hallucinates about some options.
- ❌ Claude 3.7 + No Reasoning (0s): Wrong results. Hallucination.
- ✅ Gemini 2.5 Pro + Reasoning (1m 30s): Good but doesn't provide enough details on a couple of reasoning steps
- ✅ o3 (1m 13s): Good. Interesting. It assumes knowledge of very advanced concepts — not surprising at this level. The answer is very well structured.
- ❌ GPT-4o (0s): Wrong results. Hallucination.
Solution example:
Example of o3’s answer;
Takeaway: When it comes to brain-bending problems, there's a clear winner's circle. o3 and Gemini 2.5 Pro really shine here (and Claude 3.7 with reasoning enabled isn't too shabby either).
What's really cool about o3 is how it consistently delivers super-organized, crystal-clear answers - no matter how complex the problem gets. Gemini, while smart, sometimes gets a bit messy with the explanations.
Now, I know what you're thinking:
WHAT ABOUT CODING?
Fair question! I actually skipped coding tests for a couple of good reasons:
- First off, most coding tasks (unless you're trying to build the next God of War from scratch and in one shot) can be handled pretty well by the regular models out there like Claude 3.5 or 3.7. Though I'll admit, Gemini 2.5 Pro and o3 are absolute beasts when it comes to dev work.
- Second, there are already tons of coding benchmarks out there. I wanted to focus on something different - seeing how these "genius models" handle complex reasoning and truly PhD-level problems.
Based on our testing, it's pretty clear - unless you're tackling some seriously brain-bending advanced tasks, o3 or Gemini 2.5 Pro might be overkill. For your everyday AI needs, simpler models like GPT-4o often do the job just fine (and sometimes even better!).
And here's a head-scratcher: o4-mini's performance was surprisingly underwhelming across the board (I really miss o3-mini). 🤔
🔚 Final Verdict
The hype machine is loud.
But here’s the quiet truth:
Most of the time, you don’t need the “genius” models.
You need reliability.
You need clarity.
You need answers that make sense and don’t take 90 seconds of computation to get there.
For casual use?
Stick with 4o or Claude 3.7. They're already a very very good models. You don't need 1m reasoning steps.
For deep reasoning, strategy, complex math, serious analysis, or when "regular models" fail?
o3 and Gemini 2.5 Pro are your best bets.
But don’t get lost in the names.
Or the weekly releases.
Or the AI hype Olympics.
Here’s the game now:
- Most “models” are decent.
- Some “agents” are exceptional.
- They’re only as useful as your ability to use them — for your task.
The best users in 2025 aren’t those with the flashiest tools. They’re the ones who know how to use them.
Until next time,
—Charafeddine
PS: If you’re still working without AI tools in 2025, it’s either because you’re a purist… or you enjoy pain.
Call me if you don’t know where to start: link